Atslēgvārds IDENTITY ir SQL Server rekvizīts. Ja tabulas kolonna ir definēta ar identitātes rekvizītu, tās vērtība būs automātiski ģenerēta pieauguma vērtība . Šo vērtību serveris izveido automātiski. Tāpēc mēs nevaram manuāli ievadīt vērtību identitātes kolonnā kā lietotājs. Tādējādi, ja mēs atzīmējam kolonnu kā identitāti, SQL Server to aizpildīs automātiskā pieauguma veidā.
Sintakse
Tālāk ir norādīta sintakse, kas ilustrē rekvizīta IDENTITY izmantošanu SQL Server:
IDENTITY[(seed, increment)]
Iepriekš minētie sintakses parametri ir izskaidroti tālāk:
Ļaujiet mums saprast šo jēdzienu, izmantojot vienkāršu piemēru.
Pieņemsim, ka mums ir Students ' galda, un mēs vēlamies Studenta ID jāģenerē automātiski. Mums ir sākuma studenta ID 10 un vēlaties to palielināt par 1 ar katru jaunu ID. Šajā scenārijā ir jādefinē šādas vērtības.
Sēkla: 10
Pieaugums: 1
CREATE TABLE Student ( StudentID INT IDENTITY(10, 1) PRIMARY KEY NOT NULL, )
PIEZĪME. Katrā tabulā SQL Server ir atļauta tikai viena identifikācijas kolonna.
SQL Server IDENTITĀTES piemērs
Ļaujiet mums saprast, kā mēs varam izmantot identitātes rekvizītu tabulā. Identitātes rekvizītu kolonnā var iestatīt vai nu tad, kad tiek izveidota jauna tabula, vai pēc tās izveides. Šeit mēs redzēsim abus gadījumus ar piemēriem.
Īpašums IDENTITY ar jaunu tabulu
Šis paziņojums izveidos jaunu tabulu ar identitātes rekvizītu norādītajā datu bāzē:
CREATE TABLE person ( PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL, Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Pēc tam šajā tabulā ievietosim jaunu rindu ar IZEJA klauzula, lai redzētu automātiski ģenerēto personas ID:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.PersonID VALUES('Sara Jackson', 'HR', 'Female');
Izpildot šo vaicājumu, tiks parādīta šāda izvade:
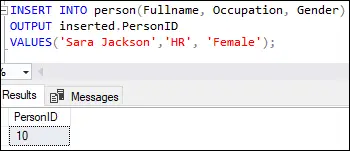
Šī izvade parāda, ka pirmā rinda ir ievietota ar vērtību desmit Personas ID kolonnu, kā norādīts tabulas definīcijas identitātes kolonnā.
Ievietosim vēl vienu rindu personu galds kā norādīts zemāk:
INSERT INTO person(Fullname, Occupation, Gender) OUTPUT inserted.* VALUES('Mark Boucher', 'Cricketer', 'Male'), ('Josh Phillip', 'Writer', 'Male');
Šis vaicājums atgriezīs šādu izvadi:

Šī izvade parāda, ka kolonnā PersonID ir ievietota otrā rinda ar vērtību 11 un trešā rinda ar vērtību 12.
IDENTITY rekvizīts ar esošu tabulu
Mēs izskaidrosim šo jēdzienu, vispirms izdzēšot iepriekš minēto tabulu un izveidojot tās bez identitātes īpašuma. Lai nomestu tabulu, izpildiet tālāk norādīto paziņojumu:
DROP TABLE person;
Tālāk mēs izveidosim tabulu, izmantojot tālāk norādīto vaicājumu:
CREATE TABLE person ( Fullname VARCHAR(100) NOT NULL, Occupation VARCHAR(50), Gender VARCHAR(10) NOT NULL );
Ja esošajā tabulā vēlamies pievienot jaunu kolonnu ar identitātes rekvizītu, mums ir jāizmanto komanda ALTER. Tālāk sniegtais vaicājums personu tabulā pievienos PersonID kā identitātes kolonnu:
ALTER TABLE person ADD PersonID INT IDENTITY(10,1) PRIMARY KEY NOT NULL;
Skaidra vērtības pievienošana identitātes kolonnai
Ja mēs pievienosim jaunu rindu iepriekšminētajai tabulai, skaidri norādot identitātes kolonnas vērtību, SQL Server parādīs kļūdu. Skatiet tālāk esošo vaicājumu:
INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 13);
Izpildot šo vaicājumu, tiks parādīta šāda kļūda:

Lai precīzi ievietotu identitātes kolonnas vērtību, vispirms ir jāiestata vērtība IDENTITY_INSERT ON. Pēc tam izpildiet ievietošanas darbību, lai pievienotu tabulai jaunu rindu, un pēc tam iestatiet IDENTITY_INSERT vērtību OFF. Skatiet zemāk esošo koda skriptu:
SET IDENTITY_INSERT person ON /*INSERT VALUE*/ INSERT INTO person(Fullname, Occupation, Gender, PersonID) VALUES('Mary Smith', 'Business Analyst', 'Female', 14); SET IDENTITY_INSERT person OFF SELECT * FROM person;
IDENTITY_INSERT IESL ļauj lietotājiem ievietot datus identitātes kolonnās IDENTITY_INSERT OFF neļauj tiem pievienot vērtību šai kolonnai.
Koda skripta izpildes laikā tiks parādīta zemāk redzamā izvade, kurā mēs varam redzēt, ka personas ID ar vērtību 14 ir veiksmīgi ievietots.

IDENTITĀTE Funkcija
SQL Server nodrošina dažas identitātes funkcijas darbam ar tabulas IDENTITY kolonnām. Šīs identitātes funkcijas ir uzskaitītas zemāk:
- @@IDENTITĀTE Funkcija
- SCOPE_IDENTITY() funkcija
- IDENT_CURRENT Funkcija
- IDENTITĀTE Funkcija
Apskatīsim IDENTITĀTES funkcijas ar dažiem piemēriem.
@@IDENTITĀTE Funkcija
@@IDENTITY ir sistēmas definēta funkcija, kas parāda pēdējo identitātes vērtību (maksimālā izmantotā identitātes vērtība), kas izveidots tabulā IDENTITĀTES kolonnai tajā pašā sesijā. Šī funkcijas kolonna atgriež identitātes vērtību, ko ģenerē priekšraksts pēc jauna ieraksta ievietošanas tabulā. Tas atgriež a NULL vērtība, kad izpildām vaicājumu, kas nerada IDENTITĀTES vērtības. Tas vienmēr darbojas pašreizējās sesijas ietvaros. To nevar izmantot attālināti.
Piemērs
Pieņemsim, ka pašreizējā maksimālā identitātes vērtība personu tabulā ir 13. Tagad mēs tajā pašā sesijā pievienosim vienu ierakstu, kas palielina identitātes vērtību par vienu. Pēc tam mēs izmantosim funkciju @@IDENTITY, lai iegūtu pēdējo tajā pašā sesijā izveidoto identitātes vērtību.
Šeit ir pilns koda skripts:
SELECT MAX(PersonID) AS maxidentity FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Brian Lara', 'Cricket', 'Male'); SELECT @@IDENTITY;
Izpildot skriptu, tiks atgriezta šāda izvade, kurā mēs varam redzēt, ka maksimālā izmantotā identitātes vērtība ir 14.

SCOPE_IDENTITY() funkcija
SCOPE_IDENTITY() ir sistēmas definēta funkcija parādīt jaunāko identitātes vērtību tabulā saskaņā ar pašreizējo darbības jomu. Šī joma var būt modulis, aktivizētājs, funkcija vai saglabāta procedūra. Tā ir līdzīga funkcijai @@IDENTITY(), taču šai funkcijai ir tikai ierobežota darbības joma. Funkcija SCOPE_IDENTITY atgriež NULL, ja mēs to izpildām pirms ievietošanas darbības, kas ģenerē vērtību tajā pašā tvērumā.
Piemērs
Tālāk norādītajā kodā vienā sesijā tiek izmantota gan funkcija @@IDENTITY, gan SCOPE_IDENTITY(). Šajā piemērā vispirms tiks parādīta pēdējā identitātes vērtība, pēc tam tabulā tiks ievietota viena rinda. Tālāk tas izpilda abas identitātes funkcijas.
SELECT MAX(PersonID) AS maxid FROM person; INSERT INTO person(Fullname, Occupation, Gender) VALUES('Jennifer Winset', 'Actoress', 'Female'); SELECT SCOPE_IDENTITY(); SELECT @@IDENTITY;
Izpildot kodu, pašreizējā sesijā tiks parādīta viena un tā pati vērtība un līdzīgs apjoms. Skatiet zemāk redzamo izvades attēlu:

Tagad mēs redzēsim, kā abas funkcijas atšķiras, izmantojot piemēru. Pirmkārt, mēs izveidosim divas tabulas ar nosaukumu darbinieka_dati un nodaļa izmantojot tālāk norādīto paziņojumu:
CREATE TABLE employee_data ( emp_id INT IDENTITY(1, 1) PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL ) GO CREATE TABLE department ( department_id INT IDENTITY(100, 5) PRIMARY KEY, department_name VARCHAR(20) NULL );
Pēc tam tabulā darbinieku_dati izveidojam INSERT aktivizētāju. Šis trigeris tiek izsaukts, lai nodaļas tabulā ievietotu rindu ikreiz, kad ievietojam rindu tabulā darbinieku_dati.
Tālāk sniegtais vaicājums izveido trigeri noklusējuma vērtības ievietošanai 'TĀ' nodaļas tabulā katrā ievietojiet vaicājumu tabulā darbinieka_dati:
min max
CREATE TRIGGER Insert_Department ON employee_data FOR INSERT AS BEGIN INSERT INTO department VALUES ('IT') END;
Pēc trigera izveides mēs ievietosim vienu ierakstu darbinieku_datu tabulā un redzēsim gan @@IDENTITY, gan SCOPE_IDENTITY() funkciju izvadi.
INSERT INTO employee_data VALUES ('John Mathew');
Izpildot vaicājumu, tabulai darbinieka_dati tiks pievienota viena rinda un tajā pašā sesijā tiks ģenerēta identitātes vērtība. Kad ievietošanas vaicājums ir izpildīts tabulā darbinieka_dati, tas automātiski izsauc trigeri, lai nodaļas tabulā pievienotu vienu rindu. Identitātes sākuma vērtība ir 1 darbinieka_datiem un 100 nodaļas tabulai.
Visbeidzot, mēs izpildām tālāk norādītos paziņojumus, kas parāda izvadi 100 funkcijai SELECT @@IDENTITY un 1 funkcijai SCOPE_IDENTITY, jo tie atgriež identitātes vērtību tikai tajā pašā tvērumā.
SELECT MAX(emp_id) FROM employee_data SELECT MAX(department_id) FROM department SELECT @@IDENTITY SELECT SCOPE_IDENTITY()
Lūk, rezultāts:

IDENT_CURRENT() Funkcija
IDENT_CURRENT ir sistēmas definēta funkcija parādīt jaunāko IDENTITĀTES vērtību ģenerēts noteiktai tabulai jebkurā savienojumā. Šī funkcija neņem vērā SQL vaicājuma jomu, kas rada identitātes vērtību. Šai funkcijai ir nepieciešams tabulas nosaukums, kurai mēs vēlamies iegūt identitātes vērtību.
Piemērs
Mēs to varam saprast, vispirms atverot abus savienojuma logus. Mēs ievietosim vienu ierakstu pirmajā logā, kas ģenerē identitātes vērtību 15 personu tabulā. Tālāk mēs varam pārbaudīt šo identitātes vērtību citā savienojuma logā, kur mēs varam redzēt to pašu izvadi. Šeit ir pilns kods:
1st Connection Window INSERT INTO person(Fullname, Occupation, Gender) VALUES('John Doe', 'Engineer', 'Male'); GO SELECT MAX(PersonID) AS maxid FROM person; 2nd Connection Window SELECT MAX(PersonID) AS maxid FROM person; GO SELECT IDENT_CURRENT('person') AS identity_value;
Izpildot iepriekš minētos kodus divos dažādos logos, tiks parādīta viena un tā pati identitātes vērtība.

IDENTITĀTE() Funkcija
Funkcija IDENTITY() ir sistēmas definēta funkcija izmanto identitātes kolonnas ievietošanai jaunā tabulā . Šī funkcija atšķiras no rekvizīta IDENTITY, ko izmantojam ar priekšrakstiem CREATE TABLE un ALTER TABLE. Šo funkciju varam izmantot tikai priekšrakstā SELECT INTO, kas tiek izmantots, pārsūtot datus no vienas tabulas uz citu.
Šī sintakse ilustrē šīs funkcijas izmantošanu SQL Server:
IDENTITY (data_type , seed , increment) AS column_name
Ja avota tabulai ir kolonna IDENTITY, tabula, kas izveidota ar komandu SELECT INTO, to pārmanto pēc noklusējuma. Piemēram , mēs iepriekš esam izveidojuši tabulas personu ar identitātes kolonnu. Pieņemsim, ka mēs izveidojam jaunu tabulu, kas manto personu tabulu, izmantojot SELECT INTO priekšrakstus ar funkciju IDENTITY(). Tādā gadījumā mēs saņemsim kļūdu, jo avota tabulā jau ir identitātes kolonna. Skatiet tālāk esošo vaicājumu:
SELECT IDENTITY(INT, 100, 2) AS NEW_ID, PersonID, Fullname, Occupation, Gender INTO person_info FROM person;
Izpildot iepriekš minēto paziņojumu, tiks parādīts šāds kļūdas ziņojums:

Izveidosim jaunu tabulu bez identitātes rekvizīta, izmantojot tālāk norādīto paziņojumu:
CREATE TABLE student_data ( roll_no INT PRIMARY KEY NOT NULL, fullname VARCHAR(20) NULL )
Pēc tam kopējiet šo tabulu, izmantojot priekšrakstu SELECT INTO, ieskaitot funkciju IDENTITĀTE, kā norādīts tālāk.
SELECT IDENTITY(INT, 100, 1) AS student_id, roll_no, fullname INTO temp_data FROM student_data;
Kad paziņojums ir izpildīts, mēs varam to pārbaudīt, izmantojot sp_help komanda, kas parāda tabulas rekvizītus.

Kolonnu IDENTITĀTE varat redzēt sadaļā KĀRDINĀMS īpašības atbilstoši norādītajiem nosacījumiem.
Ja mēs izmantojam šo funkciju ar priekšrakstu SELECT, SQL Server parādīs šādu kļūdas ziņojumu:
Ziņojums 177, 15. līmenis, 1. stāvoklis, 2. rinda Funkciju IDENTITY var izmantot tikai tad, ja priekšrakstam SELECT ir INTO klauzula.
Atkārtoti tiek izmantotas IDENTITY vērtības
Mēs nevaram atkārtoti izmantot identitātes vērtības tabulā SQL Server. Dzēšot jebkuru rindu no identitātes kolonnas tabulas, identitātes kolonnā tiks izveidota atstarpe. Turklāt SQL Server radīs atstarpi, kad identitātes kolonnā ievietosim jaunu rindu un paziņojums neizdevās vai tiks atsaukts. Atstarpe norāda, ka identitātes vērtības ir pazaudētas un tās nevar ģenerēt atkārtoti kolonnā IDENTITĀTE.
Apsveriet tālāk sniegto piemēru, lai to saprastu praktiski. Mums jau ir personu tabula, kurā ir šādi dati:

Tālāk mēs izveidosim vēl divas tabulas ar nosaukumu 'pozīcija' , un ' personas_pozīcija ' izmantojot šādu paziņojumu:
CREATE TABLE POSITION ( PositionID INT IDENTITY (1, 1) PRIMARY KEY, Position_name VARCHAR (255) NOT NULL ); CREATE TABLE person_position ( PersonID INT, PositionID INT, PRIMARY KEY (PersonID, PositionID), FOREIGN KEY (PersonID) REFERENCES person (PersonID), FOREIGN KEY (PositionID) REFERENCES POSITION (PositionID) );
Tālāk mēs mēģinām ievietot jaunu ierakstu personu tabulā un piešķirt tām pozīciju, pievienojot jaunu rindu tabulā person_position. Mēs to darīsim, izmantojot tālāk norādīto darījuma paziņojumu.
BEGIN TRANSACTION BEGIN TRY -- insert a new row into the person table INSERT INTO person (Fullname, Occupation, Gender) VALUES('Joan Smith', 'Manager', 'Male'); -- assign a position to a new person INSERT INTO person_position (PersonID, PositionID) VALUES(@@IDENTITY, 10); END TRY BEGIN CATCH IF @@TRANCOUNT > 0 ROLLBACK TRANSACTION; END CATCH IF @@TRANCOUNT > 0 COMMIT TRANSACTION;
Iepriekš minētais darījuma koda skripts veiksmīgi izpilda pirmo ievietošanas priekšrakstu. Bet otrais apgalvojums neizdevās, jo pozīciju tabulā nebija pozīcijas ar id desmit. Tādējādi viss darījums tika atcelts.
Tā kā mūsu maksimālā identitātes vērtība kolonnā PersonID ir 16, pirmais ievietošanas priekšraksts izmantoja identitātes vērtību 17, un pēc tam darījums tika atsaukts. Tāpēc, ja tabulā Persona ievietosim nākamo rindu, nākamā identitātes vērtība būs 18. Izpildiet tālāk norādīto paziņojumu:
INSERT INTO person(Fullname, Occupation, Gender) VALUES('Peter Drucker',' Writer', 'Female');
Atkārtoti pārbaudot personu tabulu, mēs redzam, ka tikko pievienotajā ierakstā ir identitātes vērtība 18.

Divas IDENTITY kolonnas vienā tabulā
Tehniski nav iespējams izveidot divas identitātes kolonnas vienā tabulā. Ja mēs to darām, SQL Server rada kļūdu. Skatiet šādu vaicājumu:
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, ID2 INT IDENTITY (100, 1) NOT NULL )
Kad mēs izpildīsim šo kodu, mēs redzēsim šādu kļūdu:

Tomēr mēs varam izveidot divas identitātes kolonnas vienā tabulā, izmantojot aprēķināto kolonnu. Šis vaicājums izveido tabulu ar aprēķinātu kolonnu, kas izmanto sākotnējo identitātes kolonnu un samazina to par 1.
CREATE TABLE TwoIdentityTable ( ID1 INT IDENTITY (10, 1) NOT NULL, SecondID AS 10000-ID1, Descriptions VARCHAR(60) )
Tālāk mēs pievienosim dažus datus šai tabulai, izmantojot tālāk norādīto komandu:
INSERT INTO TwoIdentityTable (Descriptions) VALUES ('Javatpoint provides best educational tutorials'), ('www.javatpoint.com')
Visbeidzot, mēs pārbaudām tabulas datus, izmantojot SELECT priekšrakstu. Tas atgriež šādu izvadi:

Attēlā redzams, kā kolonna SecondID darbojas kā otrā identitātes kolonna, kas samazinās par desmit no sākuma vērtības 9990.
SQL Server kolonnas IDENTITĀTE maldīgi priekšstati
DBA lietotājam ir daudz nepareizu priekšstatu par SQL Server identitātes kolonnām. Tālāk ir sniegts saraksts ar visbiežāk sastopamajiem maldīgajiem priekšstatiem par identitātes kolonnām, kas būtu redzami.
Sleja IDENTITĀTE ir UNIKĀLA: Saskaņā ar SQL Server oficiālo dokumentāciju identitātes rekvizīts nevar garantēt, ka kolonnas vērtība ir unikāla. Lai ieviestu kolonnas unikalitāti, mums ir jāizmanto PRIMĀRĀ ATSLĒGA, UNIKĀLS ierobežojums vai UNIKĀLS indekss.
Kolonna IDENTITY ģenerē secīgus skaitļus: Oficiālajā dokumentācijā ir skaidri norādīts, ka identitātes kolonnā piešķirtās vērtības var tikt zaudētas datu bāzes kļūmes vai servera restartēšanas gadījumā. Ievietošanas laikā tas var radīt nepilnības identitātes vērtībā. Atstarpi var izveidot arī tad, kad mēs izdzēšam vērtību no tabulas vai ievietošanas priekšraksts tiek atvilkts atpakaļ. Vērtības, kas rada nepilnības, nevar izmantot tālāk.
Slejā IDENTITY nevar automātiski ģenerēt esošās vērtības: Identitātes kolonnai nav iespējams automātiski ģenerēt esošās vērtības, kamēr identitātes rekvizīts nav atkārtoti iesēts, izmantojot komandu DBCC CHECKIDENT. Tas ļauj mums pielāgot identitātes rekvizīta sākuma vērtību (rindas sākuma vērtību). Pēc šīs komandas izpildes SQL Server nepārbaudīs jaunizveidotās vērtības, kas jau ir tabulā.
Lai identificētu rindu, pietiek ar sleju IDENTITĀTE kā PRIMĀRĀ ATSLĒGA: Ja primārajā atslēgā ir identitātes kolonna tabulā bez citiem unikāliem ierobežojumiem, kolonna var saglabāt dublētās vērtības un novērst kolonnas unikalitāti. Kā zināms, primārā atslēga nevar saglabāt dublikātu vērtības, bet identitātes kolonna var saglabāt dublikātus; ir ieteicams neizmantot primāro atslēgu un identitātes rekvizītus vienā kolonnā.
Nepareiza rīka izmantošana, lai pēc ievietošanas atgūtu identitātes vērtības: Tas ir arī izplatīts nepareizs priekšstats par to, ka nezina atšķirības starp @@IDENTITY, SCOPE_IDENTITY(), IDENT_CURRENT un IDENTITY() funkcijām, lai identitātes vērtība tiktu tieši ievietota no tikko izpildītā paziņojuma.
Atšķirība starp SEQUENCE un IDENTITY
Automātisko numuru ģenerēšanai mēs izmantojam gan SEQUENCE, gan IDENTITY. Tomēr tai ir dažas atšķirības, un galvenā atšķirība ir tā, ka identitāte ir atkarīga no tabulas, bet secība nav atkarīga. Apkoposim to atšķirības tabulas veidā:
| IDENTITĀTE | SECĪBA |
|---|---|
| Identitātes rekvizīts tiek izmantots noteiktai tabulai, un to nevar koplietot ar citām tabulām. | DBA definē secības objektu, ko var koplietot starp vairākām tabulām, jo tas ir neatkarīgs no tabulas. |
| Šis rekvizīts automātiski ģenerē vērtības katru reizi, kad tabulā tiek izpildīts ievietošanas priekšraksts. | Tas izmanto klauzulu NEXT VALUE FOR, lai ģenerētu secības objekta nākamo vērtību. |
| SQL Server neatiestata identitātes rekvizīta kolonnas vērtību uz sākotnējo vērtību. | SQL Server var atiestatīt secības objekta vērtību. |
| Mēs nevaram iestatīt maksimālo vērtību identitātes īpašumam. | Mēs varam iestatīt maksimālo vērtību secības objektam. |
| Tas ir ieviests SQL Server 2000. | Tas ir ieviests SQL Server 2012. |
| Šis rekvizīts nevar ģenerēt identitātes vērtību dilstošā secībā. | Tas var ģenerēt vērtības dilstošā secībā. |
Secinājums
Šajā rakstā ir sniegts pilnīgs pārskats par IDENTITY rekvizītu SQL Server. Šeit mēs uzzinājām, kā un kad tiek izmantots identitātes īpašums, tās dažādās funkcijas, maldīgi priekšstati un kā tas atšķiras no secības.