Kas ir LRU kešatmiņa?
Kešatmiņas aizstāšanas algoritmi ir efektīvi izstrādāti, lai aizstātu kešatmiņu, kad vieta ir pilna. The Vismazāk lietots (LRU) ir viens no šiem algoritmiem. Kā norāda nosaukums, kad kešatmiņa ir pilna, LRU atlasa datus, kas ir vismazāk izmantoti, un noņem tos, lai atbrīvotu vietu jaunajiem datiem. Kešatmiņā esošo datu prioritāte mainās atkarībā no šo datu nepieciešamības, t.i., ja daži dati tiek ielādēti vai atjaunināti nesen, tad šo datu prioritāte tiks mainīta un piešķirta augstākajai prioritātei, un datu prioritāte samazinās, ja tā paliek neizmantotas operācijas pēc operācijām.
Satura rādītājs
- Kas ir LRU kešatmiņa?
- Darbības LRU kešatmiņā:
- LRU kešatmiņas darbība:
- LRU kešatmiņas ieviešanas veidi:
- LRU kešatmiņas ieviešana, izmantojot rindu un jaukšanu:
- LRU kešatmiņas ieviešana, izmantojot divkārši saistīto sarakstu un jaukšanu:
- LRU kešatmiņas ieviešana, izmantojot Deque & Hashmap:
- LRU kešatmiņas ieviešana, izmantojot Stack & Hashmap:
- LRU kešatmiņa, izmantojot Counter Implementation:
- LRU kešatmiņas ieviešana, izmantojot Lazy Updates:
- LRU kešatmiņas sarežģītības analīze:
- LRU kešatmiņas priekšrocības:
- LRU kešatmiņas trūkumi:
- LRU kešatmiņas reālā lietojumprogramma:
LRU algoritms ir standarta problēma, un tas var mainīties atkarībā no vajadzības, piemēram, operētājsistēmās LRU Tam ir izšķiroša nozīme, jo to var izmantot kā lapas aizstāšanas algoritmu, lai samazinātu lappušu kļūdas.
Darbības LRU kešatmiņā:
- LRUCache (ietilpība c): Inicializējiet LRU kešatmiņu ar pozitīva izmēra ietilpību c.
- saņemt (atslēgu) : atgriež atslēgas vērtību k' ja tas atrodas kešatmiņā, pretējā gadījumā tas atgriež -1. Atjaunina arī datu prioritāti LRU kešatmiņā.
- likt (atslēga, vērtība): Atjauniniet atslēgas vērtību, ja šī atslēga pastāv, pretējā gadījumā pievienojiet atslēgas vērtību pāri kešatmiņai. Ja atslēgu skaits pārsniedz LRU kešatmiņas ietilpību, noraidiet vismazāk izmantoto atslēgu.
LRU kešatmiņas darbība:
Pieņemsim, ka mums ir LRU kešatmiņa ar ietilpību 3, un mēs vēlētos veikt šādas darbības:
- Ievietojiet (key=1, value=A) kešatmiņā
- Ievietojiet (atslēga = 2, vērtība = B) kešatmiņā
- Ievietojiet (key=3, value=C) kešatmiņā
- Iegūstiet (atslēga=2) no kešatmiņas
- Iegūstiet (atslēga=4) no kešatmiņas
- Ievietojiet (key=4, value=D) kešatmiņā
- Ievietojiet (key=3, value=E) kešatmiņā
- Iegūstiet (atslēga=4) no kešatmiņas
- Ievietojiet (key=1, value=A) kešatmiņā
Iepriekš minētās darbības tiek veiktas viena pēc otras, kā parādīts zemāk esošajā attēlā:
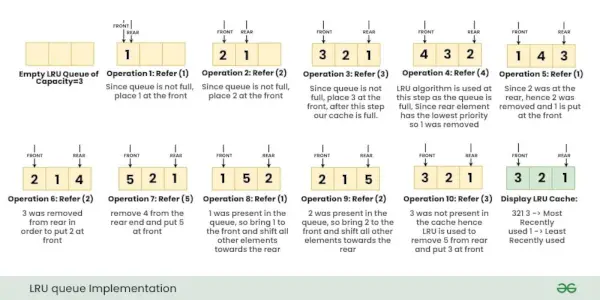
Detalizēts katras darbības skaidrojums:
- Put (1. atslēga, A vērtība) : Tā kā LRU kešatmiņā ir tukša ietilpība = 3, nav nepieciešama nomaiņa, un mēs ievietojam {1 : A} augšpusē, t.i., {1 : A} ir augstākā prioritāte.
- Put (2. atslēga, B vērtība) : Tā kā LRU kešatmiņā ir tukša ietilpība = 2, atkal nav nepieciešama nomaiņa, bet tagad {2 : B} ir augstākā prioritāte un prioritāte ir {1 : A} samazinājums.
- Put (3. atslēga, vērtība C) : Kešatmiņā joprojām ir 1 brīva vieta, tāpēc ievietojiet {3 : C} bez aizstāšanas, ievērojiet, ka tagad kešatmiņa ir pilna un pašreizējā prioritātes secība no augstākās līdz zemākajai ir {3:C}, {2:B }, {1:A}.
- Iegūt (2. atslēga) : Tagad šīs darbības laikā atgriežat atslēgas vērtību 2, arī tāpēc, ka tiek izmantota atslēga 2, tagad jaunā prioritātes secība ir {2:B}, {3:C}, {1:A}
- Iegūt (4. atslēga): Ievērojiet, ka atslēgas 4 nav kešatmiņā, mēs atgriežam “-1” šai darbībai.
- Put (4. atslēga, D vērtība) : ievērojiet, vai kešatmiņa ir PILNA, tagad izmantojiet LRU algoritmu, lai noteiktu, kura atslēga ir izmantota vismazāk. Tā kā {1:A} bija vismazākā prioritāte, noņemiet {1:A} no mūsu kešatmiņas un ievietojiet {4:D} kešatmiņā. Ņemiet vērā, ka jaunā prioritātes secība ir {4:D}, {2:B}, {3:C}
- Put (3. atslēga, vērtība E) : Tā kā atslēga = 3 jau bija kešatmiņā ar vērtību = C, šī darbība neizraisīs nevienas atslēgas noņemšanu, bet gan atjauninās atslēgas = 3 vērtību uz ' UN' . Tagad jaunā prioritātes secība kļūs par {3:E}, {4:D}, {2:B}
- Iegūt (4. atslēga) : atgriež atslēgas vērtību =4. Tagad jaunā prioritāte būs {4:D}, {3:E}, {2:B}
- Put (1. atslēga, A vērtība) : Tā kā mūsu kešatmiņa ir PILNA, izmantojiet mūsu LRU algoritmu, lai noteiktu, kura atslēga tika izmantota vismazāk, un, tā kā atslēgai {2:B} bija vismazākā prioritāte, noņemiet {2:B} no mūsu kešatmiņas un ievietojiet {1:A} kešatmiņa. Tagad jaunā prioritātes secība ir {1:A}, {4:D}, {3:E}
LRU kešatmiņas ieviešanas veidi:
LRU kešatmiņu var ieviest dažādos veidos, un katrs programmētājs var izvēlēties citu pieeju. Tomēr tālāk ir norādītas visbiežāk izmantotās metodes:
- LRU, izmantojot rindu un jaukšanu
- LRU izmantojot Divkārši saistīts saraksts + jaukšana
- LRU, izmantojot Deque
- LRU, izmantojot Stack
- LRU izmantojot Counter ieviešana
- LRU, izmantojot Lazy Updates
LRU kešatmiņas ieviešana, izmantojot rindu un jaukšanu:
Mēs izmantojam divas datu struktūras, lai ieviestu LRU kešatmiņu.
- Rinda tiek ieviests, izmantojot divkārši saistītu sarakstu. Maksimālais rindas lielums būs vienāds ar kopējo pieejamo kadru skaitu (kešatmiņas lielums). Pēdējās izmantotās lapas atradīsies tuvu priekšpusei un vismazāk izmantotās lapas būs tuvu aizmugurei.
- Hašs ar lapas numuru kā atslēgu un atbilstošā rindas mezgla adresi kā vērtību.
Atsaucoties uz lapu, vajadzīgā lapa var būt atmiņā. Ja tas ir atmiņā, mums ir jāatvieno saraksta mezgls un jānogādā tas rindas priekšgalā.
Ja vajadzīgā lapa nav atmiņā, mēs to ievietojam atmiņā. Vienkāršiem vārdiem sakot, mēs pievienojam jaunu mezglu rindas priekšpusē un atjauninām atbilstošo mezgla adresi jaucējkodā. Ja rinda ir pilna, t.i., visi kadri ir pilni, mēs noņemam mezglu no rindas aizmugures un pievienojam jauno mezglu rindas priekšpusē.
Ilustrācija:
Apskatīsim operācijas, Atsaucas taustiņu x ar LRU kešatmiņā: { 1, 2, 3, 4, 1, 2, 5, 1, 2, 3 }
Piezīme: Sākotnēji atmiņā nav nevienas lapas.Zemāk redzamajos attēlos soli pa solim parādīta iepriekš minēto darbību izpilde LRU kešatmiņā.
rudyard kipling ja paskaidrojums
Algoritms:
- Izveidojiet klasi LRUCache, deklarējot int tipa sarakstu, nesakārtotu tipa karti
- LRUcache atsauces funkcijā
- Ja šīs vērtības rindā nav, nospiediet šo vērtību rindas priekšā un noņemiet pēdējo vērtību, ja rinda ir pilna
- Ja vērtība jau ir, noņemiet to no rindas un ievietojiet to rindas priekšpusē
- Displeja funkcijā drukājiet LRUCache, izmantojot rindu, sākot no priekšpuses
Tālāk ir aprakstīta iepriekš minētās pieejas īstenošana.
C++
// We can use stl container list as a double> // ended queue to store the cache keys, with> // the descending time of reference from front> // to back and a set container to check presence> // of a key. But to fetch the address of the key> // in the list using find(), it takes O(N) time.> // This can be optimized by storing a reference> // (iterator) to each key in a hash map.> #include> using> namespace> std;> > class> LRUCache {> >// store keys of cache> >list<>int>>dq;>> // store references of key in cache> >unordered_map<>int>, list<>int>>::iterators> ma;>> csize;>// maximum capacity of cache> > public>:> >LRUCache(>int>);> >void> refer(>int>);> >void> display();> };> > // Declare the size> LRUCache::LRUCache(>int> n) { csize = n; }> > // Refers key x with in the LRU cache> void> LRUCache::refer(>int> x)> {> >// not present in cache> >if> (ma.find(x) == ma.end()) {> >// cache is full> >if> (dq.size() == csize) {> >// delete least recently used element> >int> last = dq.back();> > >// Pops the last element> >dq.pop_back();> > >// Erase the last> >ma.erase(last);> >}> >}> > >// present in cache> >else> >dq.erase(ma[x]);> > >// update reference> >dq.push_front(x);> >ma[x] = dq.begin();> }> > // Function to display contents of cache> void> LRUCache::display()> {> > >// Iterate in the deque and print> >// all the elements in it> >for> (>auto> it = dq.begin(); it != dq.end(); it++)> >cout << (*it) <<>' '>;> > >cout << endl;> }> > // Driver Code> int> main()> {> >LRUCache ca(4);> > >ca.refer(1);> >ca.refer(2);> >ca.refer(3);> >ca.refer(1);> >ca.refer(4);> >ca.refer(5);> >ca.display();> > >return> 0;> }> // This code is contributed by Satish Srinivas> |
>
pyspark
>
C
// A C program to show implementation of LRU cache> #include> #include> > // A Queue Node (Queue is implemented using Doubly Linked> // List)> typedef> struct> QNode {> >struct> QNode *prev, *next;> >unsigned> >pageNumber;>// the page number stored in this QNode> } QNode;> > // A Queue (A FIFO collection of Queue Nodes)> typedef> struct> Queue {> >unsigned count;>// Number of filled frames> >unsigned numberOfFrames;>// total number of frames> >QNode *front, *rear;> } Queue;> > // A hash (Collection of pointers to Queue Nodes)> typedef> struct> Hash {> >int> capacity;>// how many pages can be there> >QNode** array;>// an array of queue nodes> } Hash;> > // A utility function to create a new Queue Node. The queue> // Node will store the given 'pageNumber'> QNode* newQNode(unsigned pageNumber)> {> >// Allocate memory and assign 'pageNumber'> >QNode* temp = (QNode*)>malloc>(>sizeof>(QNode));> >temp->pageNumber = lapasNumurs;>> // Initialize prev and next as NULL> >temp->iepriekšējais = temp->nākamais = NULL;>> return> temp;> }> > // A utility function to create an empty Queue.> // The queue can have at most 'numberOfFrames' nodes> Queue* createQueue(>int> numberOfFrames)> {> >Queue* queue = (Queue*)>malloc>(>sizeof>(Queue));> > >// The queue is empty> >queue->skaits = 0;>> // Number of frames that can be stored in memory> >queue->skaitsOframes = skaitsOframes;>> return> queue;> }> > // A utility function to create an empty Hash of given> // capacity> Hash* createHash(>int> capacity)> {> >// Allocate memory for hash> >Hash* hash = (Hash*)>malloc>(>sizeof>(Hash));> >hash->jauda = jauda;>> // Create an array of pointers for referring queue nodes> >hash->masīvs>> malloc>(hash->ietilpība *>> > >// Initialize all hash entries as empty> >int> i;> >for> (i = 0; i capacity; ++i)> >hash->masīvs[i] = NULL;>> return> hash;> }> > // A function to check if there is slot available in memory> int> AreAllFramesFull(Queue* queue)> {> >return> queue->count == queue->numberOframes;>> // A utility function to check if queue is empty> int> isQueueEmpty(Queue* queue)> {> >return> queue->aizmugure == NULL;>> // A utility function to delete a frame from queue> void> deQueue(Queue* queue)> {> >if> (isQueueEmpty(queue))> >return>;> > >// If this is the only node in list, then change front> >if> (queue->priekšā == rinda->aizmugure)> >queue->priekšpuse = NULL;>> // Change rear and remove the previous rear> >QNode* temp = queue->aizmugure;>> if> (queue->aizmugurē)>> free>(temp);> > >// decrement the number of full frames by 1> >queue->skaitīt —;>> // A function to add a page with given 'pageNumber' to both> // queue and hash> void> Enqueue(Queue* queue, Hash* hash, unsigned pageNumber)> {> >// If all frames are full, remove the page at the rear> >if> (AreAllFramesFull(queue)) {> >// remove page from hash> >hash->masīvs[rinda->aizmugure->lapas numurs] = NULL;>> >}> > >// Create a new node with given page number,> >// And add the new node to the front of queue> >QNode* temp = newQNode(pageNumber);> >temp->nākamais = rinda->priekšpuse;>> // If queue is empty, change both front and rear> >// pointers> >if> (isQueueEmpty(queue))> >queue->aizmugure = rinda->priekšpuse = temp;>> // Else change the front> >{> >queue->front->prev = temp;>> > >// Add page entry to hash also> >hash->masīvs[lapasNumurs] = temp;>> // increment number of full frames> >queue->skaitīt++;>> // This function is called when a page with given> // 'pageNumber' is referenced from cache (or memory). There> // are two cases:> // 1. Frame is not there in memory, we bring it in memory> // and add to the front of queue> // 2. Frame is there in memory, we move the frame to front> // of queue> void> ReferencePage(Queue* queue, Hash* hash,> >unsigned pageNumber)> {> >QNode* reqPage = hash->masīvs[lapasNumurs];>> // the page is not in cache, bring it> >if> (reqPage == NULL)> >Enqueue(queue, hash, pageNumber);> > >// page is there and not at front, change pointer> >else> if> (reqPage != queue->priekšpuse) {> >// Unlink rquested page from its current location> >// in queue.> >reqPage->prev->next = reqPage->next;>> (reqPage->nākamais)>> // If the requested page is rear, then change rear> >// as this node will be moved to front> >if> (reqPage == queue->aizmugurē) {> >queue->aizmugure = reqPage->iepriekšējā;>> > >// Put the requested page before current front> >reqPage->nākamais = rinda->priekšpuse;>> // Change prev of current front> >reqPage->nākamais->iepriekšējais = reqPage;>> // Change front to the requested page> >queue->front = reqPage;>> }> > // Driver code> int> main()> {> >// Let cache can hold 4 pages> >Queue* q = createQueue(4);> > >// Let 10 different pages can be requested (pages to be> >// referenced are numbered from 0 to 9> >Hash* hash = createHash(10);> > >// Let us refer pages 1, 2, 3, 1, 4, 5> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 2);> >ReferencePage(q, hash, 3);> >ReferencePage(q, hash, 1);> >ReferencePage(q, hash, 4);> >ReferencePage(q, hash, 5);> > >// Let us print cache frames after the above referenced> >// pages> >printf>(>'%d '>, q->front->pageNumber);>> (>'%d '>, q->priekšā->nākamais->lapas numurs);>> (>'%d '>, q->priekšā->nākamais->nākamais->lapas numurs);>> (>'%d '>, q->priekšā->nākamais->nākamais->nākamais->lapas numurs);>> return> 0;> }> |
>
>
Java
/* We can use Java inbuilt Deque as a double> >ended queue to store the cache keys, with> >the descending time of reference from front> >to back and a set container to check presence> >of a key. But remove a key from the Deque using> >remove(), it takes O(N) time. This can be> >optimized by storing a reference (iterator) to> >each key in a hash map. */> import> java.util.Deque;> import> java.util.HashSet;> import> java.util.Iterator;> import> java.util.LinkedList;> > public> class> LRUCache {> > >// store keys of cache> >private> Deque doublyQueue;> > >// store references of key in cache> >private> HashSet hashSet;> > >// maximum capacity of cache> >private> final> int> CACHE_SIZE;> > >LRUCache(>int> capacity)> >{> >doublyQueue =>new> LinkedList();> >hashSet =>new> HashSet();> >CACHE_SIZE = capacity;> >}> > >/* Refer the page within the LRU cache */> >public> void> refer(>int> page)> >{> >if> (!hashSet.contains(page)) {> >if> (doublyQueue.size() == CACHE_SIZE) {> >int> last = doublyQueue.removeLast();> >hashSet.remove(last);> >}> >}> >else> {>/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.remove(page);> >}> >doublyQueue.push(page);> >hashSet.add(page);> >}> > >// display contents of cache> >public> void> display()> >{> >Iterator itr = doublyQueue.iterator();> >while> (itr.hasNext()) {> >System.out.print(itr.next() +>' '>);> >}> >}> > >// Driver code> >public> static> void> main(String[] args)> >{> >LRUCache cache =>new> LRUCache(>4>);> >cache.refer(>1>);> >cache.refer(>2>);> >cache.refer(>3>);> >cache.refer(>1>);> >cache.refer(>4>);> >cache.refer(>5>);> >cache.display();> >}> }> // This code is contributed by Niraj Kumar> |
>
>
Python3
# We can use stl container list as a double> # ended queue to store the cache keys, with> # the descending time of reference from front> # to back and a set container to check presence> # of a key. But to fetch the address of the key> # in the list using find(), it takes O(N) time.> # This can be optimized by storing a reference> # (iterator) to each key in a hash map.> class> LRUCache:> ># store keys of cache> >def> __init__(>self>, n):> >self>.csize>=> n> >self>.dq>=> []> >self>.ma>=> {}> > > ># Refers key x with in the LRU cache> >def> refer(>self>, x):> > ># not present in cache> >if> x>not> in> self>.ma.keys():> ># cache is full> >if> len>(>self>.dq)>=>=> self>.csize:> ># delete least recently used element> >last>=> self>.dq[>->1>]> > ># Pops the last element> >ele>=> self>.dq.pop();> > ># Erase the last> >del> self>.ma[last]> > ># present in cache> >else>:> >del> self>.dq[>self>.ma[x]]> > ># update reference> >self>.dq.insert(>0>, x)> >self>.ma[x]>=> 0>;> > ># Function to display contents of cache> >def> display(>self>):> > ># Iterate in the deque and print> ># all the elements in it> >print>(>self>.dq)> > # Driver Code> ca>=> LRUCache(>4>)> > ca.refer(>1>)> ca.refer(>2>)> ca.refer(>3>)> ca.refer(>1>)> ca.refer(>4>)> ca.refer(>5>)> ca.display()> # This code is contributed by Satish Srinivas> |
>
>
iemet java izņēmumu apstrādi
C#
// C# program to implement the approach> > using> System;> using> System.Collections.Generic;> > class> LRUCache {> >// store keys of cache> >private> List<>int>>doubleQueue;>> // store references of key in cache> >private> HashSet<>int>>hashSet;>> // maximum capacity of cache> >private> int> CACHE_SIZE;> > >public> LRUCache(>int> capacity)> >{> >doublyQueue =>new> List<>int>>();>> new> HashSet<>int>>();>> >}> > >/* Refer the page within the LRU cache */> >public> void> Refer(>int> page)> >{> >if> (!hashSet.Contains(page)) {> >if> (doublyQueue.Count == CACHE_SIZE) {> >int> last> >= doublyQueue[doublyQueue.Count - 1];> >doublyQueue.RemoveAt(doublyQueue.Count - 1);> >hashSet.Remove(last);> >}> >}> >else> {> >/* The found page may not be always the last> >element, even if it's an intermediate> >element that needs to be removed and added> >to the start of the Queue */> >doublyQueue.Remove(page);> >}> >doublyQueue.Insert(0, page);> >hashSet.Add(page);> >}> > >// display contents of cache> >public> void> Display()> >{> >foreach>(>int> page>in> doublyQueue)> >{> >Console.Write(page +>' '>);> >}> >}> > >// Driver code> >static> void> Main(>string>[] args)> >{> >LRUCache cache =>new> LRUCache(4);> >cache.Refer(1);> >cache.Refer(2);> >cache.Refer(3);> >cache.Refer(1);> >cache.Refer(4);> >cache.Refer(5);> >cache.Display();> >}> }> > // This code is contributed by phasing17> |
>
>
kas ir hashset java
Javascript
// JS code to implement the approach> class LRUCache {> >constructor(n) {> >this>.csize = n;> >this>.dq = [];> >this>.ma =>new> Map();> >}> > >refer(x) {> >if> (!>this>.ma.has(x)) {> >if> (>this>.dq.length ===>this>.csize) {> >const last =>this>.dq[>this>.dq.length - 1];> >this>.dq.pop();> >this>.ma.>delete>(last);> >}> >}>else> {> >this>.dq.splice(>this>.dq.indexOf(x), 1);> >}> > >this>.dq.unshift(x);> >this>.ma.set(x, 0);> >}> > >display() {> >console.log(>this>.dq);> >}> }> > const cache =>new> LRUCache(4);> > cache.refer(1);> cache.refer(2);> cache.refer(3);> cache.refer(1);> cache.refer(4);> cache.refer(5);> cache.display();> > // This code is contributed by phasing17> |
>
>
LRU kešatmiņas ieviešana, izmantojot divkārši saistīto sarakstu un jaukšanu :
Ideja ir ļoti vienkārša, t.i., turpiniet ievietot elementus galvā.
- ja elements nav iekļauts sarakstā, pievienojiet to saraksta sākumā
- ja elements ir sarakstā, pārvietojiet elementu uz galveni un pārvietojiet pārējo saraksta elementu
Ņemiet vērā, ka mezgla prioritāte būs atkarīga no šī mezgla attāluma no galvas, jo vistuvāk mezgls atrodas galvai, jo augstāka ir tā prioritāte. Tātad, kad kešatmiņas lielums ir pilns un mums ir jānoņem kāds elements, mēs noņemam elementu, kas atrodas blakus divkārši saistītā saraksta astei.
objekts Java
LRU kešatmiņas ieviešana, izmantojot Deque & Hashmap:
Deque datu struktūra ļauj ievietot un dzēst gan no priekšpuses, gan no gala, šis rekvizīts ļauj ieviest LRU, jo priekšējais elements var būt augstas prioritātes elements, savukārt beigu elements var būt zemas prioritātes elements, t.i., vismazāk izmantotais.
Darbojas:
- Saņemt operāciju : pārbauda, vai atslēga pastāv kešatmiņas jaucējkartē, un izpildiet tālāk norādītos gadījumus dekvē:
- Ja atslēga ir atrasta:
- Prece tiek uzskatīta par nesen lietotu, tāpēc tā tiek pārvietota uz dekas priekšpusi.
- Ar atslēgu saistītā vērtība tiek atgriezta kā rezultāts
get>darbība.- Ja atslēga netiek atrasta:
- atgriezt -1, lai norādītu, ka šādas atslēgas nav.
- Ievietošanas darbība: Vispirms pārbaudiet, vai atslēga jau pastāv kešatmiņas jaucējkartē, un izpildiet tālāk norādītos gadījumus deque
- Ja atslēga pastāv:
- Ar atslēgu saistītā vērtība tiek atjaunināta.
- Vienums tiek pārvietots uz dekas priekšpusi, jo tagad tas ir nesen izmantots.
- Ja atslēga neeksistē:
- Ja kešatmiņa ir pilna, tas nozīmē, ka ir jāievieto jauns vienums un jāizņem vismazāk izmantotā prece. Tas tiek darīts, noņemot vienumu no deque beigām un atbilstošo ierakstu no hash kartes.
- Pēc tam jaunais atslēgas-vērtības pāris tiek ievietots gan jaucējkartē, gan deque priekšpusē, lai norādītu, ka tas ir pēdējais izmantotais vienums.
LRU kešatmiņas ieviešana, izmantojot Stack & Hashmap:
LRU (vismazāk izmantotās) kešatmiņas ieviešana, izmantojot steka datu struktūru un jaukšanu, var būt nedaudz sarežģīta, jo vienkārša steka nenodrošina efektīvu piekļuvi vismazāk izmantotajam vienumam. Tomēr, lai to panāktu efektīvi, varat apvienot kaudzi ar jaucējkarti. Šeit ir augsta līmeņa pieeja tās ieviešanai:
- Izmantojiet jaucējkarti : jaucējkarte saglabās kešatmiņas atslēgu un vērtību pārus. Atslēgas tiks kartētas uz atbilstošajiem steka mezgliem.
- Izmantojiet kaudzi : steka saglabās atslēgu secību, pamatojoties uz to lietojumu. Visretāk lietotā prece būs kaudzes apakšā, bet pēdējā lietotā prece būs augšpusē
Šī pieeja nav tik efektīva, un tāpēc to neizmanto bieži.
LRU kešatmiņa, izmantojot Counter Implementation:
Katram kešatmiņas blokam būs savs LRU skaitītājs, kuram pieder skaitītāja vērtība No 0 līdz n-1} , šeit ' n ' apzīmē kešatmiņas lielumu. Bloks, kas tiek mainīts bloka nomaiņas laikā, kļūst par MRU bloku, un rezultātā tā skaitītāja vērtība tiek mainīta uz n – 1. Skaitītāja vērtības, kas ir lielākas par pieejamā bloka skaitītāja vērtību, tiek samazinātas par vienu. Pārējie bloki ir nemainīgi.
| Conter vērtība | Prioritāte | Lietots statuss |
|---|---|---|
| 0 | Zems | Vismazāk nesen lietots |
| n-1 | Augsts | Visvairāk nesen lietots |
LRU kešatmiņas ieviešana, izmantojot Lazy Updates:
LRU (vismazāk izmantotās) kešatmiņas ieviešana, izmantojot slinkus atjauninājumus, ir izplatīts paņēmiens, lai uzlabotu kešatmiņas darbību efektivitāti. Slinki atjauninājumi ietver secības izsekošanu, kādā vienumiem tiek piekļūts, nekavējoties neatjauninot visu datu struktūru. Ja notiek kešatmiņas izlaidums, varat izlemt, vai veikt pilnu atjaunināšanu, pamatojoties uz dažiem kritērijiem.
LRU kešatmiņas sarežģītības analīze:
- Laika sarežģītība:
- Operācija Put(): O(1), t.i., laiks, kas nepieciešams, lai ievietotu vai atjauninātu jaunu atslēgas vērtību pāri, ir nemainīgs
- Get() operācija: O(1), t.i., laiks, kas nepieciešams atslēgas vērtības iegūšanai, ir nemainīgs
- Palīgtelpa: O(N), kur N ir kešatmiņas ietilpība.
LRU kešatmiņas priekšrocības:
- Ātra piekļuve : Lai piekļūtu datiem no LRU kešatmiņas, nepieciešams O(1) laiks.
- Ātra atjaunināšana : Atslēgas vērtību pāra atjaunināšana LRU kešatmiņā aizņem O(1) laiku.
- Ātra vismazāk izmantoto datu noņemšana : Nepieciešams O(1) izdzēst to, kas nesen nav izmantots.
- Bez dauzīšanas: Salīdzinot ar FIFO, LRU ir mazāk uzņēmīga pret sagraušanu, jo tā ņem vērā lapu lietošanas vēsturi. Tas var noteikt, kuras lapas tiek bieži izmantotas, un noteikt tām atmiņas piešķiršanas prioritāti, samazinot lappušu kļūdu skaitu un diska I/O darbību.
LRU kešatmiņas trūkumi:
- Lai palielinātu efektivitāti, ir nepieciešams liels kešatmiņas lielums.
- Lai to ieviestu, ir jāievieš papildu datu struktūra.
- Aparatūras palīdzība ir augsta.
- LRU kļūdu noteikšana ir sarežģīta salīdzinājumā ar citiem algoritmiem.
- Tam ir ierobežota pieņemamība.
LRU kešatmiņas reālā lietojumprogramma:
- Datu bāzu sistēmās, lai ātri iegūtu vaicājumu rezultātus.
- Operētājsistēmās, lai samazinātu lapu kļūdas.
- Teksta redaktori un IDE, lai saglabātu bieži lietotus failus vai koda fragmentus
- Tīkla maršrutētāji un slēdži izmanto LRU, lai palielinātu datortīkla efektivitāti
- Kompilatoru optimizācijās
- Teksta prognozēšanas un automātiskās pabeigšanas rīki