Kā mēs zinām, uzraudzīto mašīnmācīšanās algoritmu var plaši iedalīt regresijas un klasifikācijas algoritmos. Regresijas algoritmos mēs esam paredzējuši izvadi nepārtrauktām vērtībām, bet, lai prognozētu kategoriskas vērtības, mums ir nepieciešami klasifikācijas algoritmi.
Kas ir klasifikācijas algoritms?
Klasifikācijas algoritms ir uzraudzītas mācīšanās paņēmiens, ko izmanto, lai noteiktu jaunu novērojumu kategoriju, pamatojoties uz apmācību datiem. Klasifikācijā programma mācās no dotās datu kopas vai novērojumiem un pēc tam klasificē jauno novērojumu vairākās klasēs vai grupās. Piemēram, Jā vai nē, 0 vai 1, mēstules vai ne surogātpasts, kaķis vai suns, utt. Klases var saukt par mērķiem/iezīmēm vai kategorijām.
javascript cilpai
Atšķirībā no regresijas, klasifikācijas izvades mainīgais ir kategorija, nevis vērtība, piemēram, 'zaļš vai zils', 'auglis vai dzīvnieks' utt. Tā kā klasifikācijas algoritms ir uzraudzītas mācīšanās paņēmiens, tas ņem marķētus ievades datus, kas nozīmē, ka tajā ir ievade ar atbilstošo izvadi.
Klasifikācijas algoritmā diskrēta izvades funkcija (y) tiek kartēta ar ievades mainīgo (x).
y=f(x), where y = categorical output
Labākais ML klasifikācijas algoritma piemērs ir E-pasta surogātpasta detektors .
Klasifikācijas algoritma galvenais mērķis ir identificēt dotās datu kopas kategoriju, un šos algoritmus galvenokārt izmanto, lai prognozētu kategorisko datu izvadi.
Klasifikācijas algoritmus var labāk izprast, izmantojot tālāk redzamo diagrammu. Zemāk esošajā diagrammā ir divas klases — A klase un B klase. Šīm klasēm ir līdzīgas iezīmes, kas atšķiras no citām klasēm.
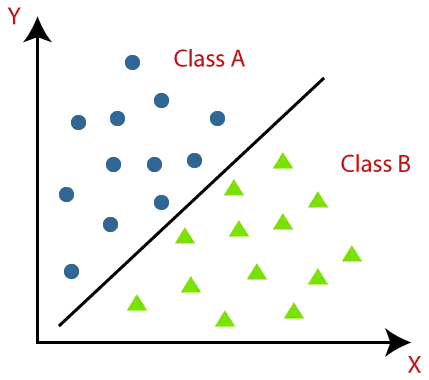
Algoritms, kas ievieš klasifikāciju datu kopā, ir pazīstams kā klasifikators. Ir divu veidu klasifikācijas:
Piemēri: JĀ vai NĒ, VĪRIETIS vai SIEVIETE, SPAMS vai NĒ SPAMS, KAĶIS vai SUNS utt.
Piemērs: Kultūraugu veidu klasifikācijas, Mūzikas veidu klasifikācija.
Audzēkņi klasifikācijas problēmās:
Klasifikācijas problēmās ir divu veidu apmācāmie:
mans monitora izmērs
Piemērs: K-NN algoritms, uz gadījumiem balstīta spriešana
ML klasifikācijas algoritmu veidi:
Klasifikācijas algoritmus var iedalīt galvenokārt divās kategorijās:
- Loģistiskā regresija
- Atbalstiet vektoru mašīnas
- K-Tuvākie kaimiņi
- Kodola SVM
- Nav Bejs
- Lēmumu koka klasifikācija
- Izlases mežu klasifikācija
Piezīme. Iepriekš minētos algoritmus mēs apgūsim turpmākajās nodaļās.
Klasifikācijas modeļa novērtēšana:
Kad mūsu modelis ir pabeigts, ir jānovērtē tā veiktspēja; vai nu tas ir klasifikācijas vai regresijas modelis. Tātad, lai novērtētu klasifikācijas modeli, mums ir šādi veidi:
1. Log loss vai Cross-Entropy Loss:
- To izmanto, lai novērtētu klasifikatora veiktspēju, kura izvade ir varbūtības vērtība no 0 līdz 1.
- Labam binārās klasifikācijas modelim log zuduma vērtībai jābūt tuvu 0.
- Log zudumu vērtība palielinās, ja prognozētā vērtība atšķiras no faktiskās vērtības.
- Mazāks log zudums nozīmē lielāku modeļa precizitāti.
- Binārajai klasifikācijai krustentropiju var aprēķināt šādi:
?(ylog(p)+(1?y)log(1?p))
Kur y = faktiskā jauda, p = paredzamā izlaide.
2. Apjukuma matrica:
- Sajaukšanas matrica nodrošina mums matricu/tabulu kā izvadi un apraksta modeļa veiktspēju.
- To sauc arī par kļūdu matricu.
- Matrica sastāv no prognožu rezultāta apkopotā formā, kurā ir kopējais pareizo prognožu un nepareizo prognožu skaits. Matrica izskatās šādi:
| Faktiski pozitīvi | Faktiskais negatīvs | |
|---|---|---|
| Paredzams pozitīvs | Patiesi Pozitīvi | Viltus pozitīvs |
| Paredzams negatīvs | Viltus negatīvs | Patiess negatīvs |

3. AUC-ROC līkne:
- ROC līkne apzīmē Uztvērēja darbības raksturlīkne un AUC apzīmē Apgabals zem līknes .
- Tas ir grafiks, kas parāda klasifikācijas modeļa veiktspēju pie dažādiem sliekšņiem.
- Lai vizualizētu vairāku klašu klasifikācijas modeļa veiktspēju, mēs izmantojam AUC-ROC līkni.
- ROC līkne ir attēlota ar TPR un FPR, kur TPR (patiesais pozitīvais ātrums) uz Y ass un FPR (viltus pozitīvais ātrums) uz X ass.
Klasifikācijas algoritmu izmantošanas gadījumi
Klasifikācijas algoritmus var izmantot dažādās vietās. Tālāk ir norādīti daži populāri klasifikācijas algoritmu lietošanas gadījumi.
- E-pasta surogātpasta noteikšana
- Runas atpazīšana
- Vēža audzēju šūnu identifikācijas.
- Narkotiku klasifikācija
- Biometriskā identifikācija utt.