Viens svarīgs aspekts Mašīnmācība ir modeļa novērtēšana. Jums ir nepieciešams kāds mehānisms, lai novērtētu savu modeli. Šeit parādās šie veiktspējas rādītāji, kas sniedz mums priekšstatu par to, cik labs ir modelis. Ja esat iepazinies ar dažiem pamatiem Mašīnmācība tad jūs noteikti esat saskāries ar dažiem no šiem rādītājiem, piemēram, precizitāte, precizitāte, atsaukšana, auc-roc utt., ko parasti izmanto klasifikācijas uzdevumiem. Šajā rakstā mēs padziļināti izpētīsim vienu šādu metriku, kas ir AUC-ROC līkne.
Satura rādītājs
- Kas ir AUC-ROC līkne?
- Galvenie termini, kas izmantoti AUC un ROC līknē
- Saikne starp jutību, specifiku, FPR un slieksni.
- Kā darbojas AUC-ROC?
- Kad mums vajadzētu izmantot AUC-ROC novērtēšanas metriku?
- Spekulējot modeļa veiktspēju
- AUC-ROC līknes izpratne
- Īstenošana, izmantojot divus dažādus modeļus
- Kā izmantot ROC-AUC vairāku klašu modelim?
- Bieži uzdotie jautājumi par AUC ROC līkni mašīnmācībā
Kas ir AUC-ROC līkne?
AUC-ROC līkne jeb Area Under the Receiver Operating Characteristic līkne ir binārā klasifikācijas modeļa veiktspējas grafisks attēlojums pie dažādiem klasifikācijas sliekšņiem. To parasti izmanto mašīnmācībā, lai novērtētu modeļa spēju atšķirt divas klases, parasti pozitīvo klasi (piemēram, slimības klātbūtne) un negatīvo klasi (piemēram, slimības neesamību).
Vispirms sapratīsim abu terminu nozīmi ROC un AUC .
- ROC : uztvērēja darbības raksturlielumi
- AUC : laukums zem līknes
Uztvērēja darbības raksturlielumu (ROC) līkne
ROC apzīmē uztvērēja darbības raksturlielumus, un ROC līkne ir binārās klasifikācijas modeļa efektivitātes grafisks attēlojums. Tas attēlo patieso pozitīvo rādītāju (TPR) pret viltus pozitīvo rādītāju (FPR) pie dažādiem klasifikācijas sliekšņiem.
Platība zem līknes (AUC) līkne:
AUC apzīmē laukumu zem līknes, un AUC līkne apzīmē laukumu zem ROC līknes. Tas mēra binārās klasifikācijas modeļa vispārējo veiktspēju. Tā kā gan TPR, gan FPR svārstās no 0 līdz 1, tāpēc laukums vienmēr būs no 0 līdz 1, un lielāka AUC vērtība norāda uz labāku modeļa veiktspēju. Mūsu galvenais mērķis ir maksimāli palielināt šo apgabalu, lai sasniegtu augstāko TPR un zemāko FPR pie noteiktā sliekšņa. AUC mēra varbūtību, ka modelis nejauši izvēlētam pozitīvam gadījumam piešķirs lielāku paredzamo varbūtību, salīdzinot ar nejauši izvēlētu negatīvu gadījumu.
Tas pārstāv varbūtība ar kuru mūsu modelis var atšķirt divas mūsu mērķī esošās klases.
ROC-AUC klasifikācijas novērtēšanas metrika
Galvenie termini, kas izmantoti AUC un ROC līknē
1. TPR un FPR
Šī ir visizplatītākā definīcija, ar kuru jūs būtu sastapies, izmantojot Google AUC-ROC. Būtībā ROC līkne ir grafiks, kas parāda klasifikācijas modeļa veiktspēju pie visiem iespējamajiem sliekšņiem (slieksnis ir noteikta vērtība, pēc kuras jūs sakāt, ka punkts pieder noteiktai klasei). Līkne ir attēlota starp diviem parametriem
- TPR - Patiesi pozitīva likme
- FPR – Viltus pozitīvs rādītājs
Pirms izpratnes, TPR un FPR ļaujiet mums ātri apskatīt apjukuma matrica .
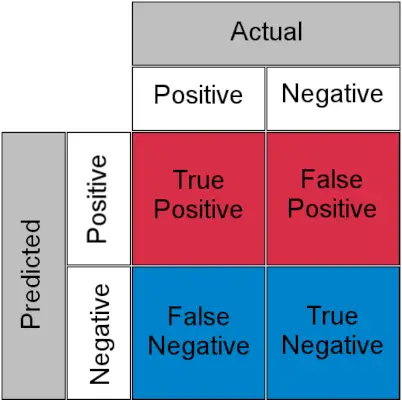
Apjukuma matrica klasifikācijas uzdevumam
- Patiesi Pozitīvi : faktiskais pozitīvs un prognozēts kā pozitīvs
- Patiess negatīvs : faktiskais negatīvais un prognozēts kā negatīvs
- Viltus pozitīvs (I tipa kļūda) : Faktiski negatīvs, bet prognozēts kā pozitīvs
- Viltus negatīvs (II tipa kļūda) : Faktiski pozitīvs, bet prognozēts kā negatīvs
Vienkārši izsakoties, jūs varat izsaukt viltus pozitīvu a viltus trauksme un viltus negatīvs a jaunkundz . Tagad apskatīsim, kas ir TPR un FPR.
2. Jutīgums / patiesi pozitīvs rādītājs / atsaukšana
Būtībā TPR / atsaukšana / jutīgums ir pareizi identificēto pozitīvo piemēru attiecība. Tas atspoguļo modeļa spēju pareizi identificēt pozitīvos gadījumus, un to aprēķina šādi:

Jutīgums/Atsaucība/TPR mēra faktisko pozitīvo gadījumu īpatsvaru, kurus modelis pareizi identificē kā pozitīvus.
3. Viltus pozitīvs rādītājs
FPR ir negatīvo piemēru attiecība, kas ir nepareizi klasificēti.

4. Specifiskums
Specifiskums mēra faktisko negatīvo gadījumu īpatsvaru, kurus modelis pareizi identificē kā negatīvus. Tas atspoguļo modeļa spēju pareizi identificēt negatīvos gadījumus

Un, kā minēts iepriekš, ROC nav nekas cits kā diagramma starp TPR un FPR visos iespējamos sliekšņos, un AUC ir viss laukums zem šīs ROC līknes.
Jutīguma un viltus pozitīvas likmes diagramma
Saikne starp jutību, specifiku, FPR un slieksni .
Jutība un specifika:
- Apgrieztā saistība: jutīgumam un specifiskumam ir apgriezta saistība. Kad viens palielinās, otram ir tendence samazināties. Tas atspoguļo raksturīgo kompromisu starp patiesi pozitīvajām un patiesi negatīvajām likmēm.
- Noskaņošana, izmantojot slieksni: Pielāgojot sliekšņa vērtību, mēs varam kontrolēt līdzsvaru starp jutīgumu un specifiskumu. Zemāki sliekšņi rada lielāku jutību (vairāk patiesu pozitīvu rezultātu) uz specifiskuma rēķina (vairāk viltus pozitīvu). Un otrādi, sliekšņa paaugstināšana palielina specifiskumu (mazāk viltus pozitīvu rezultātu), bet upurē jutīgumu (vairāk viltus negatīvu).
Slieksnis un kļūdaini pozitīvs rādītājs (FPR):
- FPR un specifikas savienojums: Viltus pozitīvs rādītājs (FPR) ir vienkārši specifiskuma papildinājums (FPR = 1 – specifiskums). Tas nozīmē tiešu saistību starp tiem: augstāka specifika nozīmē zemāku FPR un otrādi.
- FPR izmaiņas ar TPR: Līdzīgi, kā jūs novērojāt, patiesi pozitīvais rādītājs (TPR) un FPR ir arī saistīti. TPR (vairāk patieso pozitīvu) palielināšanās parasti izraisa FPR (vairāk viltus pozitīvu) pieaugumu. Un otrādi, TPR kritums (mazāk patieso pozitīvu rezultātu) izraisa FPR samazināšanos (mazāk viltus pozitīvu)
Kā darbojas AUC-ROC?
Mēs apskatījām ģeometrisko interpretāciju, bet es domāju, ka ar to joprojām nepietiek, lai attīstītu intuīciju aiz tā, ko patiesībā nozīmē 0,75 AUC, tagad apskatīsim AUC-ROC no varbūtības viedokļa. Vispirms runāsim par to, ko dara AUC, un vēlāk mēs pilnveidosim savu izpratni
AUC mēra, cik labi modelis spēj atšķirt klases.
AUC 0,75 faktiski nozīmētu, ka pieņemsim divus datu punktus, kas pieder atsevišķām klasēm, tad pastāv 75% iespēja, ka modelis spēs tos nošķirt vai sakārtot tos pareizi, t.i., pozitīvajam punktam ir lielāka prognozēšanas varbūtība nekā negatīvajam. klasē. (pieņemot augstāku prognozēšanas varbūtību, tas nozīmē, ka punkts ideālā gadījumā piederētu pozitīvajai klasei). Šeit ir neliels piemērs, lai lietas būtu skaidrākas.
Rādītājs | Klase | Varbūtība |
|---|---|---|
P1 | 1 | 0,95 |
P2 | 1 | 0,90 |
P3 | 0 | 0,85 |
P4 | 0 | 0,81 |
P5 | 1 | 0,78 |
P6 | 0 | 0,70 |
Šeit mums ir 6 punkti, kur P1, P2 un P5 pieder 1. klasei un P3, P4 un P6 pieder 0 klasei, un mēs atbilstam prognozētajām varbūtībām kolonnā Varbūtība, kā mēs teicām, ja ņemam divus punktus, kas pieder atsevišķi. klases, tad kāda ir varbūtība, ka modeļu rangs tās sakārto pareizi.
Mēs ņemsim visus iespējamos pārus tā, lai viens punkts piederētu klasei 1, bet otrs piederētu klasei 0, mums kopā būs 9 šādi pāri, un visi šie 9 iespējamie pāri.
Pāris | ir pareizs |
|---|---|
(P1, P3) | Jā |
(P1, P4) | Jā |
(P1,P6) | Jā |
(P2, P3) | Jā |
(P2, P4) | Jā |
(P2, P6) | Jā |
(P3, P5) | Nē |
(P4, P5) | Nē |
(P5,P6) | Jā |
Šeit kolonna ir Pareizi norāda, vai minētais pāris ir pareizi sakārtots, pamatojoties uz prognozēto varbūtību, t.i., 1. klases punktam ir lielāka iespējamība nekā 0 punktam, 7 no šiem 9 iespējamajiem pāriem 1. klase ir ierindota augstāk par klasi 0, vai mēs varam teikt, ka pastāv 77% iespēja, ka, izvēloties punktu pāri, kas pieder pie atsevišķām klasēm, modelis spēs tos pareizi atšķirt. Tagad es domāju, ka jums varētu būt zināma intuīcija aiz šī AUC skaitļa. Lai kliedētu visas turpmākās šaubas, apstiprināsim to, izmantojot Scikit mācās AUC-ROC ieviešanu.
Python3
import> numpy as np> from> sklearn .metrics>import> roc_auc_score> y_true>=> [>1>,>1>,>0>,>0>,>1>,>0>]> y_pred>=> [>0.95>,>0.90>,>0.85>,>0.81>,>0.78>,>0.70>]> auc>=> np.>round>(roc_auc_score(y_true, y_pred),>3>)> print>(>'Auc for our sample data is {}'>.>format>(auc))> |
>
>
Izvade:
AUC for our sample data is 0.778>
Kad mums vajadzētu izmantot AUC-ROC novērtēšanas metriku?
Dažās jomās ROC-AUC izmantošana var nebūt ideāla. Gadījumos, kad datu kopa ir ļoti nelīdzsvarota, ROC līkne var sniegt pārāk optimistisku modeļa veiktspējas novērtējumu . Šī optimisma novirze rodas tāpēc, ka ROC līknes viltus pozitīvā rādītājs (FPR) var kļūt ļoti mazs, ja faktisko negatīvo gadījumu skaits ir liels.
Skatoties uz FPR formulu,

mēs novērojam ,
- Negatīvā klase ir vairākumā, FPR saucējā dominē patiesie negatīvie, kā dēļ FPR kļūst mazāk jutīgs pret izmaiņām prognozēs, kas saistītas ar mazākuma klasi (pozitīvo klasi).
- ROC līknes var būt piemērotas, ja viltus pozitīvu un viltus negatīvu izmaksas ir līdzsvarotas un datu kopa nav ļoti nelīdzsvarota.
Tādā gadījumā Precizitātes-atgādināšanas līknes var izmantot, kas nodrošina alternatīvu novērtējuma metriku, kas ir vairāk piemērota nelīdzsvarotām datu kopām, koncentrējoties uz klasifikatora veiktspēju attiecībā uz pozitīvo (mazākuma) klasi.
Spekulējot modeļa veiktspēju
- Augsts AUC (tuvu 1) norāda uz izcilu diskriminācijas spēku. Tas nozīmē, ka modelis ir efektīvs, lai atšķirtu abas klases, un tā prognozes ir ticamas.
- Zems AUC (tuvu 0) liecina par sliktu veiktspēju. Šajā gadījumā modelis cīnās, lai atšķirtu pozitīvās un negatīvās klases, un tā prognozes var nebūt uzticamas.
- AUC aptuveni 0,5 nozīmē, ka modelis būtībā izdara nejaušus minējumus. Tas parāda, ka nav iespējams nodalīt klases, norādot, ka modelis no datiem neapgūst nekādus nozīmīgus modeļus.
AUC-ROC līknes izpratne
ROC līknē x ass parasti apzīmē viltus pozitīvo ātrumu (FPR), bet y ass apzīmē patieso pozitīvo ātrumu (TPR), kas pazīstams arī kā jutīgums vai atsaukšana. Tātad augstāka x ass vērtība (virzienā pa labi) ROC līknē norāda uz augstāku viltus pozitīvo rādītāju, un augstāka y ass vērtība (virzienā uz augšu) norāda uz augstāku patiesi pozitīvo ātrumu. ROC līkne ir grafiska kompromisa attēlojums starp patiesi pozitīvo un viltus pozitīvo rādītāju pie dažādiem sliekšņiem. Tas parāda klasifikācijas modeļa veiktspēju pie dažādiem klasifikācijas sliekšņiem. AUC (Area Under the Curve) ir ROC līknes veiktspējas kopsavilkuma mērs. Sliekšņa izvēle ir atkarīga no konkrētās problēmas, kuru mēģināt atrisināt, prasībām un kompromisa starp viltus pozitīviem un viltus negatīviem. pieņemams jūsu kontekstā.
- Ja vēlaties noteikt par prioritāti viltus pozitīvu rezultātu samazināšanu (samazinot iespēju, ka kaut kas tiks atzīmēts kā pozitīvs, ja tas tā nav), varat izvēlēties slieksni, kas rada zemāku viltus pozitīvu rezultātu skaitu.
- Ja vēlaties piešķirt prioritāti patieso pozitīvo rādītāju palielināšanai (iegūstot pēc iespējas vairāk faktisko pozitīvo), varat izvēlēties slieksni, kas nodrošina augstāku patieso pozitīvo rādītāju.
Apskatīsim piemēru, lai ilustrētu, kā ROC līknes tiek ģenerētas dažādiem sliekšņi un kā konkrētais slieksnis atbilst sajaukšanas matricai. Pieņemsim, ka mums ir a Binārās klasifikācijas problēma ar modeli, kas paredz, vai e-pasts ir surogātpasts (pozitīvs) vai nav surogātpasts (negatīvs).
Apskatīsim hipotētiskos datus,
Patiesās iezīmes: [1, 0, 1, 0, 1, 1, 0, 0, 1, 0]
Paredzamās varbūtības: [0,8, 0,3, 0,6, 0,2, 0,7, 0,9, 0,4, 0,1, 0,75, 0,55]
1. gadījums: slieksnis = 0,5
Īstas etiķetes | Paredzamās varbūtības | Paredzamās etiķetes |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 1 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 1 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Apjukuma matrica, pamatojoties uz iepriekš minētajām prognozēm
| Prognoze = 0 | Prognoze = 1 |
|---|---|---|
Faktiskais = 0 | TP=4 | FN=1 |
Faktiskais = 1 | FP=0 | TN=5 |
Attiecīgi,
- Patiesi pozitīvais rādītājs (TPR) :
Klasifikatora pareizi identificēto faktisko pozitīvo daļu īpatsvars ir

- Viltus pozitīvs rādītājs (FPR) :
Faktisko negatīvo īpatsvars, kas nepareizi klasificēti kā pozitīvi



Tātad pie 0,5 sliekšņa:
- Patiesi pozitīvais rādītājs (jutīgums): 0,8
- Viltus pozitīvs rādītājs: 0
Interpretācija ir tāda, ka modelis pie šī sliekšņa pareizi identificē 80% faktisko pozitīvo (TPR), bet nepareizi klasificē 0% faktisko negatīvo kā pozitīvo (FPR).
Attiecīgi dažādiem sliekšņiem mēs iegūsim ,
2. gadījums: slieksnis = 0,7
Īstas etiķetes | Paredzamās varbūtības | Paredzamās etiķetes |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 0 pievienojot virkni java |
| 1 | 0.6 | 0 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 0 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 0 |
Apjukuma matrica, pamatojoties uz iepriekš minētajām prognozēm
| Prognoze = 0 | Prognoze = 1 |
|---|---|---|
Faktiskais = 0 | TP=5 | FN=0 |
Faktiskais = 1 | FP=2 | TN=3 |
Attiecīgi,
- Patiesi pozitīvais rādītājs (TPR) :
Klasifikatora pareizi identificēto faktisko pozitīvo daļu īpatsvars ir

- Viltus pozitīvs rādītājs (FPR) :
Faktisko negatīvo īpatsvars, kas nepareizi klasificēti kā pozitīvi



3. gadījums: slieksnis = 0,4
Īstas etiķetes | Paredzamās varbūtības | Paredzamās etiķetes |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 1 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 1 |
| 1 | 0.9 java vienāds metode | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Apjukuma matrica, pamatojoties uz iepriekš minētajām prognozēm
| Prognoze = 0 | Prognoze = 1 |
|---|---|---|
Faktiskais = 0 | TP=4 | FN=1 |
Faktiskais = 1 | FP=0 | TN=5 |
Attiecīgi,
- Patiesi pozitīvais rādītājs (TPR) :
Klasifikatora pareizi identificēto faktisko pozitīvo daļu īpatsvars ir
- Viltus pozitīvs rādītājs (FPR) :
Faktisko negatīvo īpatsvars, kas nepareizi klasificēti kā pozitīvi
4. gadījums: slieksnis = 0,2
Īstas etiķetes | Paredzamās varbūtības | Paredzamās etiķetes |
|---|---|---|
| 1 | 0.8 | 1 |
| 0 | 0.3 | 1 |
| 1 | 0.6 | 1 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 1 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 1 |
| 0 | 0.1 | 0 |
| 1 | 0,75 | 1 |
| 0 | 0,55 | 1 |
Apjukuma matrica, pamatojoties uz iepriekš minētajām prognozēm
| Prognoze = 0 | Prognoze = 1 |
|---|---|---|
Faktiskais = 0 | TP=2 | FN=3 |
Faktiskais = 1 | FP=0 | TN=5 |
Attiecīgi,
- Patiesi pozitīvais rādītājs (TPR) :
Klasifikatora pareizi identificēto faktisko pozitīvo daļu īpatsvars ir

- Viltus pozitīvs rādītājs (FPR) :
Faktisko negatīvo īpatsvars, kas nepareizi klasificēti kā pozitīvi

5. gadījums: slieksnis = 0,85
Īstas etiķetes | Paredzamās varbūtības | Paredzamās etiķetes |
|---|---|---|
| 1 | 0.8 | 0 |
| 0 | 0.3 | 0 |
| 1 | 0.6 | 0 |
| 0 | 0.2 | 0 |
| 1 | 0.7 | 0 |
| 1 | 0.9 | 1 |
| 0 | 0.4 | 0 |
| 0 | 0.1 | 0 |
| 1 | 0,75 | 0 |
| 0 | 0,55 | 0 |
Apjukuma matrica, pamatojoties uz iepriekš minētajām prognozēm
| Prognoze = 0 | Prognoze = 1 |
|---|---|---|
Faktiskais = 0 | TP=5 | FN=0 |
Faktiskais = 1 | FP=4 | TN=1 |
Attiecīgi,
- Patiesi pozitīvais rādītājs (TPR) :
Klasifikatora pareizi identificēto faktisko pozitīvo daļu īpatsvars ir
- Viltus pozitīvs rādītājs (FPR) :
Faktisko negatīvo īpatsvars, kas nepareizi klasificēti kā pozitīvi


Pamatojoties uz iepriekš minēto rezultātu, mēs uzzīmēsim ROC līkni
Python3
true_positive_rate>=> [>0.4>,>0.8>,>0.8>,>1.0>,>1>]> false_positive_rate>=> [>0>,>0>,>0>,>0.2>,>0.8>]> plt.plot(false_positive_rate, true_positive_rate,>'o-'>, label>=>'ROC'>)> plt.plot([>0>,>1>], [>0>,>1>],>'--'>, color>=>'grey'>, label>=>'Worst case'>)> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curve'>)> plt.legend()> plt.show()> |
>
>
Izvade:
No diagrammas izriet, ka:
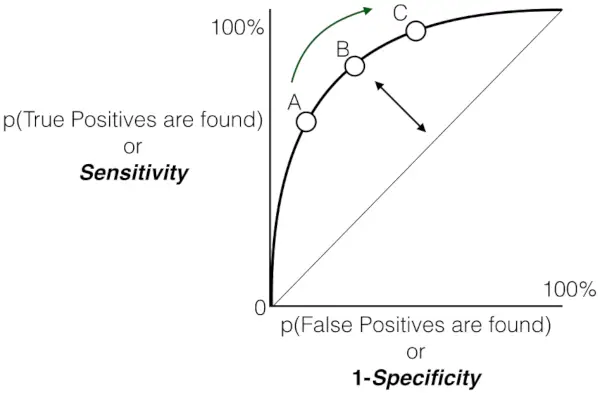
- Pelēkā punktētā līnija apzīmē sliktāko scenāriju, kur modeļa prognozes, t.i., TPR ir FPR, ir vienādas. Šī diagonālā līnija tiek uzskatīta par sliktāko scenāriju, kas norāda uz vienādu viltus pozitīvu un viltus negatīvu iespējamību.
- Punktiem novirzoties no nejaušās minēšanas līnijas augšējā kreisā stūra virzienā, modeļa veiktspēja uzlabojas.
- Apgabals zem līknes (AUC) ir modeļa diskriminācijas spēju kvantitatīvais rādītājs. Augstāka AUC vērtība, kas ir tuvāka 1,0, norāda uz izcilu veiktspēju. Labākā iespējamā AUC vērtība ir 1,0, kas atbilst modelim, kas sasniedz 100% jutību un 100% specifiskumu.
Kopumā uztvērēja darbības raksturlieluma (ROC) līkne kalpo kā grafisks kompromisa attēlojums starp binārā klasifikācijas modeļa patieso pozitīvo ātrumu (jutību) un viltus pozitīvo ātrumu pie dažādiem lēmuma sliekšņiem. Tā kā līkne graciozi paceļas virzienā uz augšējo kreiso stūri, tas norāda uz modeļa slavējamo spēju atšķirt pozitīvos un negatīvos gadījumus dažādos ticamības sliekšņos. Šī augšupejošā trajektorija norāda uz uzlabotu veiktspēju ar lielāku jutību, vienlaikus samazinot viltus pozitīvus rezultātus. Anotētie sliekšņi, kas apzīmēti kā A, B, C, D un E, sniedz vērtīgu ieskatu modeļa dinamiskajā uzvedībā dažādos ticamības līmeņos.
Īstenošana, izmantojot divus dažādus modeļus
Bibliotēku instalēšana
Python3
import> numpy as np> import> pandas as pd> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> |
>
>
Lai apmācītu Izlases mežs un Loģistiskā regresija modeļus un lai parādītu to ROC līknes ar AUC rādītājiem, algoritms izveido mākslīgus bināros klasifikācijas datus.
Datu ģenerēšana un datu sadalīšana
Python3
# Generate synthetic data for demonstration> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>2>, random_state>=>42>)> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y, test_size>=>0.2>, random_state>=>42>)> |
>
>
Izmantojot 80-20 sadalījuma attiecību, algoritms izveido mākslīgus bināros klasifikācijas datus ar 20 pazīmēm, sadala tos apmācības un testēšanas komplektos un piešķir nejaušu sēklu, lai nodrošinātu reproducējamību.
Dažādu modeļu apmācība
Python3
# Train two different models> logistic_model>=> LogisticRegression(random_state>=>42>)> logistic_model.fit(X_train, y_train)> random_forest_model>=> RandomForestClassifier(n_estimators>=>100>, random_state>=>42>)> random_forest_model.fit(X_train, y_train)> |
>
>
Izmantojot fiksētu nejaušu sēklu, lai nodrošinātu atkārtojamību, metode inicializē un apmāca loģistikas regresijas modeli apmācības komplektā. Līdzīgā veidā tas izmanto apmācības datus un to pašu nejaušo sēklu, lai inicializētu un apmācītu Random Forest modeli ar 100 kokiem.
Prognozes
Python3
# Generate predictions> y_pred_logistic>=> logistic_model.predict_proba(X_test)[:,>1>]> y_pred_rf>=> random_forest_model.predict_proba(X_test)[:,>1>]> |
>
>
Izmantojot testa datus un apmācītu Loģistiskā regresija modelim, kods prognozē pozitīvās klases varbūtību. Līdzīgā veidā, izmantojot testa datus, tas izmanto apmācītu Random Forest modeli, lai radītu prognozētās varbūtības pozitīvajai klasei.
Datu rāmja izveide
Python3
# Create a DataFrame> test_df>=> pd.DataFrame(> >{>'True'>: y_test,>'Logistic'>: y_pred_logistic,>'RandomForest'>: y_pred_rf})> |
>
>
Izmantojot testa datus, kods izveido DataFrame ar nosaukumu test_df ar kolonnām True, Logistic un RandomForest, pievienojot patiesās etiķetes un paredzamās varbūtības no izlases meža un loģistikas regresijas modeļiem.
Uzzīmējiet modeļiem ROC līkni
Python3
# Plot ROC curve for each model> plt.figure(figsize>=>(>7>,>5>))> for> model>in> [>'Logistic'>,>'RandomForest'>]:> >fpr, tpr, _>=> roc_curve(test_df[>'True'>], test_df[model])> >roc_auc>=> auc(fpr, tpr)> >plt.plot(fpr, tpr, label>=>f>'{model} (AUC = {roc_auc:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'r--'>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'ROC Curves for Two Models'>)> plt.legend()> plt.show()> |
>
>
Izvade:

Kods ģenerē diagrammu ar 8 x 6 collu skaitļiem. Tas aprēķina AUC un ROC līkni katram modelim (Random Forest un Logistic Regression), pēc tam uzzīmē ROC līkni. The ROC līkne izlases veida minējumiem tiek apzīmēta arī ar sarkanu pārtrauktu līniju, un vizualizācijai ir iestatītas etiķetes, virsraksts un leģenda.
Kā izmantot ROC-AUC vairāku klašu modelim?
Vairāku klašu iestatījumam mēs varam vienkārši izmantot metodiku viens pret visām, un katrai klasei būs viena ROC līkne. Pieņemsim, ka jums ir četras klases A, B, C un D, tad visām četrām klasēm būtu ROC līknes un atbilstošas AUC vērtības, t.i., ja A būtu viena klase un B, C un D kopā būtu pārējās klases. , līdzīgi B ir viena klase un A, C un D apvienotas kā citas klases utt.
Vispārīgie soļi AUC-ROC izmantošanai vairāku klašu klasifikācijas modeļa kontekstā ir šādi:
Metodoloģija viens pret visiem:
- Katrai vairāku klašu problēmas klasei uzskatiet to par pozitīvo klasi, vienlaikus apvienojot visas pārējās klases negatīvajā klasē.
- Apmāciet bināro klasifikatoru katrai klasei salīdzinājumā ar pārējām klasēm.
Aprēķiniet AUC-ROC katrai klasei:
- Šeit mēs attēlojam dotās klases ROC līkni pret pārējo.
- Uzzīmējiet katras klases ROC līknes vienā grafikā. Katra līkne atspoguļo modeļa diskriminācijas veiktspēju konkrētai klasei.
- Pārbaudiet katras klases AUC rādītājus. Augstāks AUC rādītājs norāda uz labāku diskrimināciju konkrētajai klasei.
AUC-ROC ieviešana vairāku klašu klasifikācijā
Bibliotēku importēšana
Python3
import> numpy as np> import> matplotlib.pyplot as plt> from> sklearn.datasets>import> make_classification> from> sklearn.model_selection>import> train_test_split> from> sklearn.preprocessing>import> label_binarize> from> sklearn.multiclass>import> OneVsRestClassifier> from> sklearn.linear_model>import> LogisticRegression> from> sklearn.ensemble>import> RandomForestClassifier> from> sklearn.metrics>import> roc_curve, auc> from> itertools>import> cycle> |
>
>
Programma izveido mākslīgus vairāku klašu datus, sadala tos apmācības un testēšanas komplektos un pēc tam izmanto Viens pret pārējo klasifikatoru tehnika, lai apmācītu klasifikatorus gan izlases meža, gan loģistikas regresijas vajadzībām. Visbeidzot, tajā ir attēlotas divu modeļu daudzklases ROC līknes, lai parādītu, cik labi tie atšķir dažādas klases.
Datu ģenerēšana un sadalīšana
Python3
# Generate synthetic multiclass data> X, y>=> make_classification(> >n_samples>=>1000>, n_features>=>20>, n_classes>=>3>, n_informative>=>10>, random_state>=>42>)> # Binarize the labels> y_bin>=> label_binarize(y, classes>=>np.unique(y))> # Split the data into training and testing sets> X_train, X_test, y_train, y_test>=> train_test_split(> >X, y_bin, test_size>=>0.2>, random_state>=>42>)> |
>
>
Trīs klases un divdesmit funkcijas veido sintētiskos vairāku klašu datus, ko rada kods. Pēc etiķetes binarizācijas dati tiek sadalīti apmācības un testēšanas komplektos proporcijā 80-20.
Apmācības modeļi
Python3
# Train two different multiclass models> logistic_model>=> OneVsRestClassifier(LogisticRegression(random_state>=>42>))> logistic_model.fit(X_train, y_train)> rf_model>=> OneVsRestClassifier(> >RandomForestClassifier(n_estimators>=>100>, random_state>=>42>))> rf_model.fit(X_train, y_train)> |
>
>
Programma apmāca divus vairāku klašu modeļus: Random Forest modeli ar 100 novērtētājiem un loģistikas regresijas modeli ar Viena pret atpūtu pieeja . Ar apmācības datu kopu tiek aprīkoti abi modeļi.
AUC-ROC līknes uzzīmēšana
Python3
# Compute ROC curve and ROC area for each class> fpr>=> dict>()> tpr>=> dict>()> roc_auc>=> dict>()> models>=> [logistic_model, rf_model]> plt.figure(figsize>=>(>6>,>5>))> colors>=> cycle([>'aqua'>,>'darkorange'>])> for> model, color>in> zip>(models, colors):> >for> i>in> range>(model.classes_.shape[>0>]):> >fpr[i], tpr[i], _>=> roc_curve(> >y_test[:, i], model.predict_proba(X_test)[:, i])> >roc_auc[i]>=> auc(fpr[i], tpr[i])> >plt.plot(fpr[i], tpr[i], color>=>color, lw>=>2>,> >label>=>f>'{model.__class__.__name__} - Class {i} (AUC = {roc_auc[i]:.2f})'>)> # Plot random guess line> plt.plot([>0>,>1>], [>0>,>1>],>'k--'>, lw>=>2>, label>=>'Random Guess'>)> # Set labels and title> plt.xlabel(>'False Positive Rate'>)> plt.ylabel(>'True Positive Rate'>)> plt.title(>'Multiclass ROC Curve with Logistic Regression and Random Forest'>)> plt.legend(loc>=>'lower right'>)> plt.show()> |
>
>
Izvade:

Meža nejaušības un loģistikas regresijas modeļu ROC līknes un AUC rādītāji tiek aprēķināti pēc katras klases koda. Pēc tam tiek uzzīmētas vairāku klašu ROC līknes, kas parāda katras klases diskriminācijas veiktspēju un ietver līniju, kas attēlo nejaušus minējumus. Iegūtais sižets piedāvā grafisku modeļu klasifikācijas veiktspējas novērtējumu.
Secinājums
Mašīnmācībā bināro klasifikācijas modeļu veiktspēja tiek novērtēta, izmantojot būtisku metriku, ko sauc par laukumu zem uztvērēja darbības raksturlielumiem (AUC-ROC). Pārsniedzot dažādus lēmumu pieņemšanas sliekšņus, tas parāda, kā jutīgums un specifiskums tiek izmainīti. Lielāku pozitīvo un negatīvo gadījumu diskrimināciju parasti parāda modelis ar augstāku AUC punktu skaitu. Kamēr 0,5 apzīmē iespēju, 1 apzīmē nevainojamu veiktspēju. Modeļa optimizāciju un izvēli palīdz AUC-ROC līkne sniegtā noderīgā informācija par modeļa spēju atšķirt klases. Strādājot ar nelīdzsvarotām datu kopām vai lietojumprogrammām, kur viltus pozitīvajiem un viltus negatīvajiem ir dažādas izmaksas, tas ir īpaši noderīgi kā visaptverošs pasākums.
Bieži uzdotie jautājumi par AUC ROC līkni mašīnmācībā
1. Kas ir AUC-ROC līkne?
Dažādiem klasifikācijas sliekšņiem kompromiss starp patiesi pozitīvo ātrumu (jutīgumu) un viltus pozitīvo ātrumu (specificitāti) ir grafiski attēlots ar AUC-ROC līkni.
2. Kā izskatās perfekta AUC-ROC līkne?
Apgabals 1 uz ideālas AUC-ROC līknes nozīmētu, ka modelis sasniedz optimālu jutību un specifiskumu pie visiem sliekšņiem.
3. Ko nozīmē AUC vērtība 0,5?
AUC 0,5 norāda, ka modeļa veiktspēja ir salīdzināma ar nejaušas nejaušības veiktspēju. Tas liecina par diskriminācijas spēju trūkumu.
4. Vai AUC-ROC var izmantot vairāku klašu klasifikācijai?
AUC-ROC bieži tiek izmantots problēmām, kas saistītas ar bināro klasifikāciju. Vairāku klašu klasifikācijā var ņemt vērā tādas variācijas kā makrovidējais vai mikrovidējais AUC.
5. Kā AUC-ROC līkne ir noderīga modeļa novērtēšanā?
Modeļa spēja atšķirt klases ir visaptveroši apkopota ar AUC-ROC līkni. Strādājot ar nelīdzsvarotām datu kopām, tas ir īpaši noderīgi.