Excel lapas ir ļoti instinktīvas un lietotājam draudzīgas, tāpēc tās ir ideāli piemērotas, lai manipulētu ar lielām datu kopām pat mazāk tehniskiem cilvēkiem. Ja meklējat vietas, kur iemācīties manipulēt un automatizēt saturu Excel failos, izmantojot Python , neskaties tālāk. Jūs esat īstajā vietā.
Šajā rakstā jūs uzzināsit, kā to izmantot Pandas strādāt ar Excel izklājlapām. Šajā rakstā mēs uzzināsim par:
- Lasīt Excel fails izmantojot Pandas programmā Python
- Pandas instalēšana un importēšana
- Vairāku Excel lapu lasīšana, izmantojot Pandas
- Dažādu Pandas funkciju pielietošana
Excel faila lasīšana, izmantojot Pandas programmā Python
Pandas uzstādīšana
Lai instalētu Pandas Python, mēs varam izmantot šādu komandu komandu uzvednē:
pip install pandas>
Lai instalētu Pandas Anaconda, mēs varam izmantot šādu komandu Anaconda terminālī:
conda install pandas>
Pandas importēšana
Pirmkārt, mums ir jāimportē Pandas modulis, ko var izdarīt, izpildot komandu:
Python3
import> pandas as pd> |
>
>
Ievades fails: Pieņemsim, ka Excel fails izskatās šādi
1. lapa:

1. lapa
2. lapa:
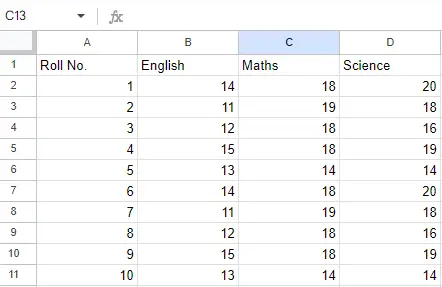
2. lapa
Tagad mēs varam importēt Excel failu, izmantojot Pandas funkciju read_excel, lai lasītu Excel failu, izmantojot Pandas programmā Python. Otrais priekšraksts nolasa datus no Excel un saglabā tos pandas datu rāmī, ko attēlo mainīgais newData.
Python3
nejauši nav ģeneratora java
df>=> pd.read_excel(>'Example.xlsx'>)> print>(df)> |
>
>
Izvade:
Roll No. English Maths Science 0 1 19 13 17 1 2 14 20 18 2 3 15 18 19 3 4 13 14 14 4 5 17 16 20 5 6 19 13 17 6 7 14 20 18 7 8 15 18 19 8 9 13 14 14 9 10 17 16 20>
Vairāku lapu ielāde, izmantojot Concat() metodi
Ja Excel darbgrāmatā ir vairākas lapas, komanda importēs datus no pirmās lapas. Lai izveidotu datu rāmi ar visām darbgrāmatas lapām, vienkāršākā metode ir izveidot dažādus datu rāmjus atsevišķi un pēc tam tos savienot. Metode read_excel izmanto argumentu lapas_nosaukums un indeksa_kola, kur mēs varam norādīt lapu, no kuras jāizveido rāmis, un index_col norāda virsraksta kolonnu, kā parādīts zemāk:
Piemērs:
Trešais paziņojums savieno abas lapas. Tagad, lai pārbaudītu visu datu rāmi, mēs varam vienkārši palaist šādu komandu:
Python3
file> => 'Example.xlsx'> sheet1>=> pd.read_excel(>file>,> >sheet_name>=> 0>,> >index_col>=> 0>)> sheet2>=> pd.read_excel(>file>,> >sheet_name>=> 1>,> >index_col>=> 0>)> # concatinating both the sheets> newData>=> pd.concat([sheet1, sheet2])> print>(newData)> |
>
>
Izvade:
Roll No. English Maths Science 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 6 19 13 17 7 14 20 18 8 15 18 19 9 13 14 14 10 17 16 20 1 14 18 20 2 11 19 18 3 12 18 16 4 15 18 19 5 13 14 14 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Head() un Tail() metodes pandās
Lai skatītu 5 kolonnas no datu rāmja augšdaļas un apakšas, mēs varam palaist komandu. Šis galva () un aste () metode arī izmanto argumentus kā skaitļus, lai parādītu kolonnu skaitu.
Python3
print>(newData.head())> print>(newData.tail())> |
>
>
Izvade:
English Maths Science Roll No. 1 19 13 17 2 14 20 18 3 15 18 19 4 13 14 14 5 17 16 20 English Maths Science Roll No. 6 14 18 20 7 11 19 18 8 12 18 16 9 15 18 19 10 13 14 14>
Shape() metode
The forma() metode var izmantot, lai skatītu rindu un kolonnu skaitu datu rāmī šādi:
Python3
newData.shape> |
>
>
Izvade:
(20, 3)>
Sort_values() metode programmā Pandas
Ja kādā kolonnā ir skaitliski dati, mēs varam kārtot šo kolonnu, izmantojot sort_values() metode pandām ir šāda:
Python3
sorted_column>=> newData.sort_values([>'English'>], ascending>=> False>)> |
>
>
Tagad pieņemsim, ka mēs vēlamies kārtotās kolonnas 5 galvenās vērtības, šeit varam izmantot head() metodi:
Python3
sorted_column.head(>5>)> |
>
>
Izvade:
English Maths Science Roll No. 1 19 13 17 6 19 13 17 5 17 16 20 10 17 16 20 3 15 18 19>
Mēs to varam izdarīt ar jebkuru datu rāmja skaitlisko kolonnu, kā parādīts zemāk:
Python3
newData[>'Maths'>].head()> |
>
>
Izvade:
Roll No. 1 13 2 20 3 18 4 14 5 16 Name: Maths, dtype: int64>
Pandas Aprakstiet() metodi
Tagad pieņemsim, ka mūsu dati lielākoties ir skaitliski. Mēs varam iegūt statistisko informāciju, piemēram, vidējo, maksimālo, minimālo utt. par datu rāmi, izmantojot aprakstīt () metode, kā parādīts zemāk:
Python3
newData.describe()> |
>
>
Izvade:
English Maths Science count 20.00000 20.000000 20.000000 mean 14.30000 16.800000 17.500000 std 2.29645 2.330575 2.164304 min 11.00000 13.000000 14.000000 25% 13.00000 14.000000 16.000000 50% 14.00000 18.000000 18.000000 75% 15.00000 18.000000 19.000000 max 19.00000 20.000000 20.000000>
To var izdarīt arī atsevišķi visām skaitliskajām kolonnām, izmantojot šādu komandu:
Python3
newData[>'English'>].mean()> |
>
>
Izvade:
14.3>
Izmantojot attiecīgās metodes, var aprēķināt arī citu statistisko informāciju. Tāpat kā programmā Excel, var izmantot arī formulas, un aprēķinātās kolonnas var izveidot šādi:
Python3
newData[>'Total Marks'>]>=> >newData[>'English'>]>+> newData[>'Maths'>]>+> newData[>'Science'>]> newData[>'Total Marks'>].head()> |
>
>
kur ir pārlūkprogrammas iestatījumi
Izvade:
Roll No. 1 49 2 52 3 52 4 41 5 53 Name: Total Marks, dtype: int64>
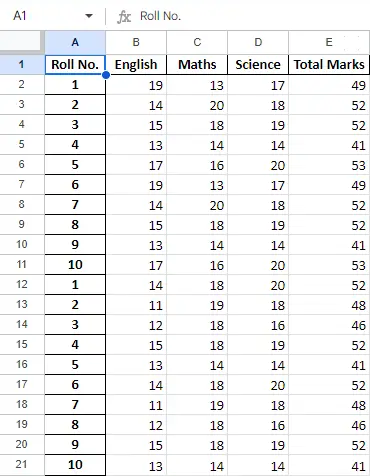
Pēc darbības ar datiem datu rāmī mēs varam eksportēt datus atpakaļ uz Excel failu, izmantojot metodi to_excel. Šim nolūkam mums ir jānorāda izvades Excel fails, kurā jāraksta pārveidotie dati, kā parādīts zemāk:
Python3
newData.to_excel(>'Output File.xlsx'>)> |
>
>
Izvade:
Noslēguma lapa