Mašīnmācība ir nozare Mākslīgais intelekts kas koncentrējas uz modeļu un algoritmu izstrādi, kas ļauj datoriem mācīties no datiem un uzlabot no iepriekšējās pieredzes, bez tiešas programmēšanas katram uzdevumam. Vienkāršiem vārdiem sakot, ML māca sistēmām domāt un saprast kā cilvēkiem, mācoties no datiem.
Šajā rakstā mēs izpētīsim dažādus veidi mašīnmācīšanās algoritmi kas ir svarīgi nākotnes prasībām. Mašīnmācība parasti ir apmācības sistēma, lai mācītos no pagātnes pieredzes un laika gaitā uzlabotu sniegumu. Mašīnmācība palīdz prognozēt milzīgu datu apjomu. Tas palīdz nodrošināt ātrus un precīzus rezultātus, lai iegūtu ienesīgas iespējas.
Mašīnmācīšanās veidi
Ir vairāki mašīnmācīšanās veidi, katram no tiem ir īpašas īpašības un lietojumi. Daži no galvenajiem mašīnmācīšanās algoritmu veidiem ir šādi:
- Uzraudzīta mašīnmācīšanās
- Mašīnmācīšanās bez uzraudzības
- Daļēji uzraudzīta mašīnmācīšanās
- Pastiprināšanas mācības
Mašīnmācīšanās veidi
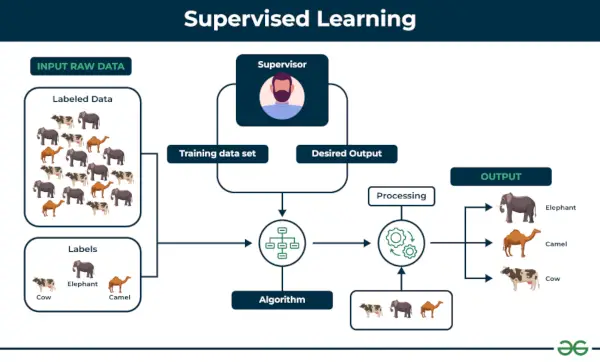
1. Uzraudzīta mašīnmācīšanās
Uzraudzīta mācīšanās tiek definēts kā tad, kad modelis tiek apmācīts a Datu kopa ar etiķeti . Marķētajām datu kopām ir gan ievades, gan izvades parametri. In Uzraudzīta mācīšanās algoritmi mācās kartēt punktus starp ieejām un pareiziem izvadiem. Tam ir marķētas gan apmācības, gan validācijas datu kopas.
Uzraudzīta mācīšanās
binārs uz bcd
Sapratīsim to ar piemēra palīdzību.
Piemērs: Apsveriet scenāriju, kurā jums ir jāizveido attēlu klasifikators, lai atšķirtu kaķus un suņus. Ja algoritmam ievadāt suņu un kaķu marķētu attēlu datu kopas, iekārta iemācīsies klasificēt suni vai kaķi no šiem marķētajiem attēliem. Ievadot jaunus suņa vai kaķa attēlus, ko tas nekad iepriekš nav redzējis, tas izmantos apgūtos algoritmus un prognozēs, vai tas ir suns vai kaķis. Lūk, kā uzraudzīta mācīšanās darbojas, un tā jo īpaši ir attēlu klasifikācija.
Tālāk ir minētas divas galvenās uzraudzītās apmācības kategorijas:
- Klasifikācija
- Regresija
Klasifikācija
Klasifikācija nodarbojas ar prognozēšanu kategorisks mērķa mainīgie, kas attēlo atsevišķas klases vai etiķetes. Piemēram, klasificējot e-pastus kā surogātpastu vai ne, vai prognozējot, vai pacientam ir augsts sirds slimību risks. Klasifikācijas algoritmi mācās kartēt ievades līdzekļus vienā no iepriekš definētajām klasēm.
Šeit ir daži klasifikācijas algoritmi:
- Loģistiskā regresija
- Atbalstiet vektoru mašīnu
- Izlases mežs
- Lēmumu koks
- K — tuvākie kaimiņi (KNN)
- Naivai Beiji
Regresija
Regresija , no otras puses, nodarbojas ar prognozēšanu nepārtraukts mērķa mainīgie, kas attēlo skaitliskas vērtības. Piemēram, prognozēt mājas cenu, pamatojoties uz tās lielumu, atrašanās vietu un ērtībām, vai prognozēt preces pārdošanas apjomu. Regresijas algoritmi iemācās kartēt ievades funkcijas uz nepārtrauktu skaitlisku vērtību.
Šeit ir daži regresijas algoritmi:
- Lineārā regresija
- Polinoma regresija
- Ridža regresija
- Laso regresija
- Lēmumu koks
- Izlases mežs
Uzraudzītas mašīnmācīšanās priekšrocības
- Uzraudzīta mācīšanās modeļiem var būt augsta precizitāte, jo tie tiek apmācīti marķēti dati .
- Lēmumu pieņemšanas process uzraudzītajos mācību modeļos bieži ir interpretējams.
- To bieži var izmantot iepriekš apmācītos modeļos, kas ietaupa laiku un resursus, izstrādājot jaunus modeļus no nulles.
Uzraudzītas mašīnmācīšanās trūkumi
- Tam ir ierobežojumi, zinot modeļus, un tas var cīnīties ar neredzamiem vai negaidītiem modeļiem, kas nav iekļauti apmācības datos.
- Tas var būt laikietilpīgs un dārgs, jo tas balstās uz to marķēti tikai dati.
- Tas var novest pie sliktiem vispārinājumiem, pamatojoties uz jauniem datiem.
Uzraudzītās mācīšanās pielietojumi
Uzraudzīta mācīšanās tiek izmantota dažādās lietojumprogrammās, tostarp:
- Attēlu klasifikācija : identificējiet attēlos objektus, sejas un citus elementus.
- Dabiskās valodas apstrāde: Izņemiet no teksta informāciju, piemēram, noskaņojumu, entītijas un attiecības.
- Runas atpazīšana : pārvērš runāto valodu tekstā.
- Ieteikumu sistēmas : sniedziet lietotājiem personalizētus ieteikumus.
- Prognozējošā analītika : prognozējiet rezultātus, piemēram, pārdošanu, klientu samazināšanos un akciju cenas.
- Medicīniskā diagnoze : Atklājiet slimības un citus veselības stāvokļus.
- Krāpšanas atklāšana : identificējiet krāpnieciskus darījumus.
- Autonomie transportlīdzekļi : atpazīt apkārtējās vides objektus un reaģēt uz tiem.
- E-pasta surogātpasta noteikšana : klasificējiet e-pastus kā surogātpastu vai ne.
- Kvalitātes kontrole ražošanā : Pārbaudiet, vai izstrādājumiem nav defektu.
- Kredīta vērtēšana : novērtējiet risku, ka aizņēmējs nepilda aizdevumu.
- Spēles : atpazīstiet varoņus, analizējiet spēlētāju uzvedību un izveidojiet NPC.
- Klientu atbalsts : automatizējiet klientu atbalsta uzdevumus.
- Laika prognoze : prognozējiet temperatūru, nokrišņus un citus meteoroloģiskos parametrus.
- Sporta analītika : analizējiet spēlētāju sniegumu, veiciet spēles prognozes un optimizējiet stratēģijas.
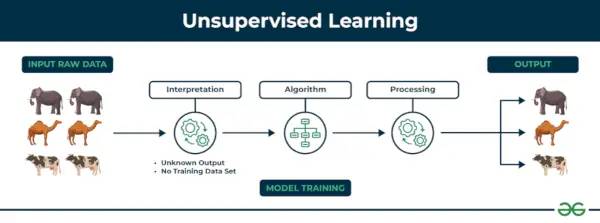
2. Mašīnmācīšanās bez uzraudzības
Mācības bez uzraudzības Nepārraudzīta mācīšanās ir mašīnmācīšanās tehnikas veids, kurā algoritms atklāj modeļus un attiecības, izmantojot nemarķētus datus. Atšķirībā no uzraudzītas mācīšanās, neuzraudzīta mācīšanās neietver algoritma nodrošināšanu ar marķētiem mērķa rezultātiem. Nepārraudzītās mācīšanās galvenais mērķis bieži ir atklāt slēptos modeļus, līdzības vai kopas datos, ko pēc tam var izmantot dažādiem mērķiem, piemēram, datu izpētei, vizualizācijai, dimensiju samazināšanai un citiem.
segmentācijas vainas kodols izmests
Mācības bez uzraudzības
Sapratīsim to ar piemēra palīdzību.
Piemērs: Apsveriet, ka jums ir datu kopa, kurā ir informācija par veikalā veiktajiem pirkumiem. Izmantojot klasterus, algoritms var grupēt to pašu pirkšanas rīcību starp jums un citiem klientiem, kas atklāj potenciālos klientus bez iepriekš definētām etiķetēm. Šāda veida informācija var palīdzēt uzņēmumiem iegūt mērķa klientus, kā arī noteikt novirzes.
Tālāk ir minētas divas galvenās nekontrolētas mācīšanās kategorijas:
- Klasterizācija
- asociācija
Klasterizācija
Klasterizācija ir datu punktu grupēšanas process klasteros, pamatojoties uz to līdzību. Šis paņēmiens ir noderīgs, lai identificētu modeļus un attiecības datos, neizmantojot marķētus piemērus.
Šeit ir daži klasterizācijas algoritmi:
- K-Means klasterizācijas algoritms
- Vidējās nobīdes algoritms
- DBSCAN algoritms
- Galvenās sastāvdaļas analīze
- Neatkarīgu komponentu analīze
asociācija
Apgūstiet asociācijas noteikumu ing ir paņēmiens, lai atklātu attiecības starp vienumiem datu kopā. Tas identificē noteikumus, kas norāda uz viena vienuma klātbūtni, nozīmē cita vienuma klātbūtni ar noteiktu varbūtību.
Šeit ir daži asociācijas noteikumu mācīšanās algoritmi:
java pāris
- Apriori algoritms
- Mirdzums
- FP izaugsmes algoritms
Neuzraudzītas mašīnmācīšanās priekšrocības
- Tas palīdz atklāt slēptos modeļus un dažādas attiecības starp datiem.
- Izmanto tādiem uzdevumiem kā klientu segmentēšana, anomāliju noteikšana, un datu izpēte .
- Tam nav nepieciešami marķēti dati, un tas samazina datu marķēšanas piepūli.
Neuzraudzītas mašīnmācīšanās trūkumi
- Neizmantojot etiķetes, var būt grūti paredzēt modeļa izvades kvalitāti.
- Klasteru interpretācija var nebūt skaidra, un tai var nebūt jēgpilnu interpretāciju.
- Tam ir tādas metodes kā autokodētāji un izmēru samazināšana ko var izmantot, lai no neapstrādātiem datiem iegūtu nozīmīgus līdzekļus.
Nepārraudzītas mācīšanās pielietojumi
Tālāk ir norādītas dažas izplatītas nekontrolētas mācīšanās lietojumprogrammas:
- Klasterizācija : grupējiet līdzīgus datu punktus klasteros.
- Anomāliju noteikšana : identificējiet datu novirzes vai anomālijas.
- Izmēru samazināšana : samaziniet datu dimensiju, vienlaikus saglabājot to būtisko informāciju.
- Ieteikumu sistēmas : Iesakiet lietotājiem produktus, filmas vai saturu, pamatojoties uz viņu vēsturisko uzvedību vai vēlmēm.
- Tēmu modelēšana : atklājiet latentās tēmas dokumentu kolekcijā.
- Blīvuma novērtējums : Novērtējiet datu varbūtības blīvuma funkciju.
- Attēlu un video saspiešana : samaziniet multivides saturam nepieciešamo krātuves apjomu.
- Datu priekšapstrāde : palīdzība ar datu pirmapstrādes uzdevumiem, piemēram, datu tīrīšanu, trūkstošo vērtību imputāciju un datu mērogošanu.
- Tirgus groza analīze : atklājiet asociācijas starp produktiem.
- Genomisko datu analīze : identificējiet modeļus vai grupējiet gēnus ar līdzīgiem ekspresijas profiliem.
- Attēlu segmentēšana : segmentējiet attēlus nozīmīgos reģionos.
- Kopienas noteikšana sociālajos tīklos : identificējiet kopienas vai personu grupas ar līdzīgām interesēm vai saiknēm.
- Klientu uzvedības analīze : atklājiet modeļus un ieskatus, lai iegūtu labākus mārketinga un produktu ieteikumus.
- Satura ieteikums : klasificējiet un atzīmējiet saturu, lai lietotājiem būtu vieglāk ieteikt līdzīgus vienumus.
- Izpētes datu analīze (EDA) : izpētiet datus un gūstiet ieskatu pirms konkrētu uzdevumu noteikšanas.
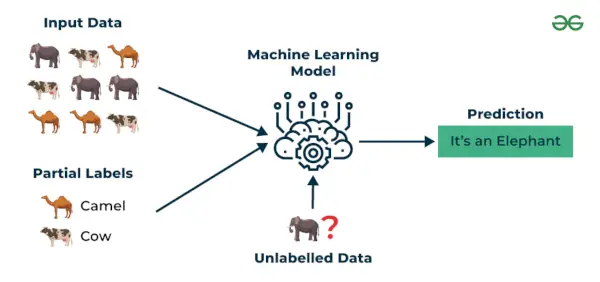
3. Daļēji uzraudzīta mācīšanās
Daļēji uzraudzīta mācīšanās ir mašīnmācīšanās algoritms, kas darbojas starp uzraudzīts un bez uzraudzības mācās, tāpēc izmanto abus marķēti un nemarķēti datus. Tas ir īpaši noderīgi, ja marķētu datu iegūšana ir dārga, laikietilpīga vai resursietilpīga. Šī pieeja ir noderīga, ja datu kopa ir dārga un laikietilpīga. Daļēji uzraudzīta mācīšanās tiek izvēlēta, ja marķētiem datiem ir vajadzīgas prasmes un atbilstoši resursi, lai apmācītu vai mācītos no tiem.
Mēs izmantojam šīs metodes, ja strādājam ar datiem, kas ir nedaudz marķēti, bet pārējā liela daļa nav marķēta. Mēs varam izmantot neuzraudzītas metodes, lai paredzētu etiķetes un pēc tam ievadītu šīs etiķetes uzraudzītām metodēm. Šis paņēmiens galvenokārt ir piemērojams attēlu datu kopām, kur parasti visi attēli nav marķēti.
Daļēji uzraudzīta apmācība
Sapratīsim to ar piemēra palīdzību.
Piemērs : Apsveriet, ka mēs veidojam valodas tulkošanas modeli, jo tulkojumu marķēšana katram teikumu pārim var būt resursietilpīga. Tas ļauj modeļiem mācīties no marķētiem un nemarķētiem teikumu pāriem, padarot tos precīzākus. Šis paņēmiens ir ļāvis būtiski uzlabot mašīntulkošanas pakalpojumu kvalitāti.
Daļēji uzraudzīto mācību metožu veidi
Ir vairākas dažādas daļēji uzraudzītas mācību metodes, kurām katrai ir savas īpašības. Daži no visizplatītākajiem ietver:
- Uz grafikiem balstīta daļēji uzraudzīta mācīšanās: Šī pieeja izmanto grafiku, lai attēlotu attiecības starp datu punktiem. Pēc tam diagrammu izmanto, lai izplatītu etiķetes no marķētajiem datu punktiem uz neiezīmētajiem datu punktiem.
- Etiķetes izplatīšana: Šī pieeja iteratīvi izplata etiķetes no marķētajiem datu punktiem uz nemarķētajiem datu punktiem, pamatojoties uz datu punktu līdzībām.
- Kopapmācība: Šī pieeja apmāca divus dažādus mašīnmācīšanās modeļus dažādām nemarķēto datu apakškopām. Pēc tam abus modeļus izmanto, lai marķētu viena otras prognozes.
- Pašapmācība: Šī pieeja apmāca mašīnmācīšanās modeli marķētajiem datiem un pēc tam izmanto modeli, lai paredzētu etiķetes nemarķētiem datiem. Pēc tam modelis tiek atkārtoti apmācīts uz iezīmētajiem datiem un paredzamajām etiķetēm nemarķētiem datiem.
- Ģeneratīvie pretrunīgie tīkli (GAN) : GAN ir dziļās mācīšanās algoritma veids, ko var izmantot sintētisko datu ģenerēšanai. GAN var izmantot, lai ģenerētu nemarķētus datus daļēji uzraudzītai apmācībai, apmācot divus neironu tīklus, ģeneratoru un diskriminatoru.
Daļēji uzraudzītas mašīnmācīšanās priekšrocības
- Tas rada labāku vispārināšanu, salīdzinot ar uzraudzīta mācīšanās, jo tiek ņemti gan marķēti, gan nemarķēti dati.
- Var attiecināt uz plašu datu klāstu.
Daļēji uzraudzītas mašīnmācīšanās trūkumi
- Daļēji uzraudzīts Metodes var būt sarežģītākas, salīdzinot ar citām pieejām.
- Tas joprojām prasa dažus marķēti dati kas var ne vienmēr būt pieejami vai viegli iegūt.
- Nemarķētie dati var attiecīgi ietekmēt modeļa veiktspēju.
Daļēji uzraudzītas mācīšanās pielietojumi
Šeit ir daži izplatīti daļēji uzraudzītas apmācības lietojumi:
- Attēlu klasifikācija un objektu atpazīšana : uzlabojiet modeļu precizitāti, apvienojot nelielu marķētu attēlu kopu ar lielāku neiezīmētu attēlu kopu.
- Dabiskās valodas apstrāde (NLP) : uzlabojiet valodu modeļu un klasifikatoru veiktspēju, apvienojot nelielu marķētu teksta datu kopu ar lielu daudzumu neiezīmēta teksta.
- Runas atpazīšana: Uzlabojiet runas atpazīšanas precizitāti, izmantojot ierobežotu transkribēto runas datu daudzumu un plašāku neiezīmētu audio kopu.
- Ieteikumu sistēmas : uzlabojiet personalizēto ieteikumu precizitāti, papildinot retu lietotāja vienumu mijiedarbības kopu (iezīmēti dati) ar daudziem neiezīmētiem lietotāju uzvedības datiem.
- Veselības aprūpe un medicīniskā attēlveidošana : uzlabojiet medicīnisko attēlu analīzi, izmantojot nelielu marķētu medicīnisko attēlu kopu kopā ar lielāku bezmarķētu attēlu kopu.
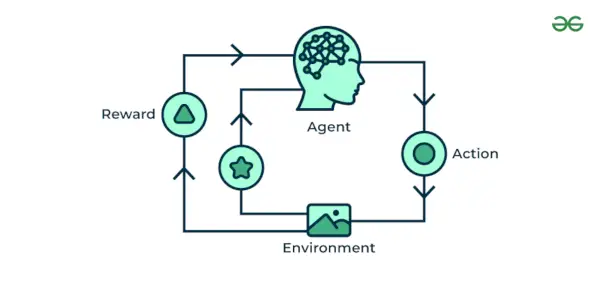
4. Pastiprināšanas mašīnmācība
Pastiprināšanas mašīnmācība algoritms ir mācību metode, kas mijiedarbojas ar vidi, veicot darbības un atklājot kļūdas. Izmēģinājums, kļūda un kavēšanās ir visatbilstošākie pastiprināšanas mācību raksturlielumi. Izmantojot šo paņēmienu, modelis turpina palielināt savu veiktspēju, izmantojot atlīdzības atsauksmes, lai uzzinātu uzvedību vai modeli. Šie algoritmi ir raksturīgi konkrētai problēmai, piemēram, Google pašpiedziņas auto, AlphaGo, kur robots sacenšas ar cilvēkiem un pat ar sevi, lai iegūtu arvien labākus rezultātus spēlē Go Game. Katru reizi, kad ievadām datus, viņi mācās un pievieno datus savām zināšanām, kas ir apmācības dati. Tātad, jo vairāk tas mācās, jo labāk tas tiek apmācīts un līdz ar to arī pieredzējis.
Šeit ir daži no visizplatītākajiem pastiprināšanas mācību algoritmiem:
- Q-mācības: Q-learning ir bez modeļa RL algoritms, kas apgūst Q-funkciju, kas sakārto stāvokļus ar darbībām. Q funkcija novērtē paredzamo atlīdzību par konkrētas darbības veikšanu noteiktā stāvoklī.
- SARSA (State-Action-Reward-State-Action): SARSA ir vēl viens bez modeļa RL algoritms, kas apgūst Q funkciju. Tomēr atšķirībā no Q-learning, SARSA atjaunina Q funkciju faktiski veiktajai darbībai, nevis optimālajai darbībai.
- Padziļināta Q apmācība : Deep Q-learning ir Q-mācību un dziļās mācīšanās kombinācija. Deep Q-learning izmanto neironu tīklu, lai attēlotu Q funkciju, kas ļauj apgūt sarežģītas attiecības starp stāvokļiem un darbībām.
Pastiprināšanas mašīnmācība
Sapratīsim to ar piemēru palīdzību.
Piemērs: Apsveriet, ka jūs trenējat AI aģents spēlēt tādu spēli kā šahs. Aģents pēta dažādas kustības un saņem pozitīvas vai negatīvas atsauksmes, pamatojoties uz rezultātu. Pastiprināšanas mācīšanās atrod arī lietojumprogrammas, kurās viņi mācās veikt uzdevumus, mijiedarbojoties ar apkārtējo vidi.
Armatūras mašīnmācības veidi
Ir divi galvenie pastiprināšanas mācību veidi:
Pozitīvs pastiprinājums
- Apbalvo aģentu par vēlamās darbības veikšanu.
- Mudina aģentu atkārtot uzvedību.
- Piemēri: cienasta iedošana sunim par sēdēšanu, punkta nodrošināšana spēlē par pareizu atbildi.
Negatīvs pastiprinājums
- Noņem nevēlamu stimulu, lai veicinātu vēlamo uzvedību.
- Attur aģentu atkārtot uzvedību.
- Piemēri: skaļa skaņas signāla izslēgšana, kad tiek nospiesta svira, izvairīšanās no soda, izpildot uzdevumu.
Armatūras mašīnmācības priekšrocības
- Tam ir autonoma lēmumu pieņemšana, kas ir labi piemērota uzdevumiem un var iemācīties pieņemt virkni lēmumu, piemēram, robotiku un spēļu spēlēšanu.
- Šis paņēmiens ir vēlams, lai sasniegtu ilgtermiņa rezultātus, kurus ir ļoti grūti sasniegt.
- To izmanto, lai atrisinātu sarežģītas problēmas, kuras nevar atrisināt ar parastajām metodēm.
Armatūras mašīnmācības trūkumi
- Apmācības pastiprināšana Mācību aģenti var būt skaitļošanas ziņā dārgi un laikietilpīgi.
- Mācību pastiprināšana nav labāka par vienkāršu problēmu risināšanu.
- Tam ir nepieciešams daudz datu un daudz aprēķinu, kas padara to nepraktisku un dārgu.
Armatūras mašīnmācības pielietojumi
Šeit ir daži pastiprināšanas mācību pielietojumi:
- Spēles spēlēšana : RL var iemācīt aģentiem spēlēt spēles, pat sarežģītas.
- Robotika : RL var iemācīt robotiem veikt uzdevumus autonomi.
- Autonomie transportlīdzekļi : RL var palīdzēt pašbraucošām automašīnām orientēties un pieņemt lēmumus.
- Ieteikumu sistēmas : RL var uzlabot ieteikumu algoritmus, apgūstot lietotāja preferences.
- Veselības aprūpe RL var izmantot, lai optimizētu ārstēšanas plānus un zāļu atklāšanu.
- Dabiskās valodas apstrāde (NLP) : RL var izmantot dialogu sistēmās un tērzēšanas robotos.
- Finanses un tirdzniecība : RL var izmantot algoritmiskai tirdzniecībai.
- Piegādes ķēdes un krājumu pārvaldība : RL var izmantot, lai optimizētu piegādes ķēdes darbības.
- Enerģijas pārvaldība : RL var izmantot, lai optimizētu enerģijas patēriņu.
- AI spēles : RL var izmantot, lai izveidotu viedākus un adaptīvākus NPC videospēlēs.
- Adaptīvie personīgie asistenti : RL var izmantot, lai uzlabotu personīgos palīgus.
- Virtuālā realitāte (VR) un paplašinātā realitāte (AR): RL var izmantot, lai radītu ieskaujošu un interaktīvu pieredzi.
- Rūpnieciskā kontrole : RL var izmantot, lai optimizētu rūpnieciskos procesus.
- Izglītība : RL var izmantot, lai izveidotu adaptīvas mācību sistēmas.
- Lauksaimniecība : RL var izmantot, lai optimizētu lauksaimniecības darbības.
Jāpārbauda, mūsu detalizētais raksts par : Mašīnmācīšanās algoritmi
Secinājums
Noslēgumā jāsaka, ka katrs mašīnmācīšanās veids kalpo savam mērķim un veicina vispārējo lomu uzlaboto datu prognozēšanas iespēju attīstībā, un tam ir potenciāls mainīt dažādas nozares, piemēram, Datu zinātne . Tas palīdz tikt galā ar masveida datu ražošanu un datu kopu pārvaldību.
Mašīnmācīšanās veidi — FAQ
1. Ar kādiem izaicinājumiem jāsaskaras vadītajā apmācībā?
Dažas no problēmām, ar kurām saskaras uzraudzītā mācīšanās, galvenokārt ietver klases nelīdzsvarotības novēršanu, augstas kvalitātes marķētus datus un izvairīšanos no pārmērīgas pielāgošanas, ja modeļi slikti darbojas reāllaika datiem.
kā pārvērst virkni par veselu skaitli
2. Kur mēs varam pielietot uzraudzīto mācīšanos?
Uzraudzīta mācīšanās parasti tiek izmantota tādiem uzdevumiem kā surogātpasta e-pasta analīze, attēlu atpazīšana un noskaņojuma analīze.
3. Kāda izskatās mašīnmācīšanās perspektīva nākotnē?
Mašīnmācība kā nākotnes perspektīva var darboties tādās jomās kā laikapstākļu vai klimata analīze, veselības aprūpes sistēmas un autonoma modelēšana.
4. Kādi ir dažādi mašīnmācīšanās veidi?
Ir trīs galvenie mašīnmācīšanās veidi:
- Uzraudzīta mācīšanās
- Mācības bez uzraudzības
- Pastiprināšanas mācības
5. Kādi ir visizplatītākie mašīnmācīšanās algoritmi?
Daži no visizplatītākajiem mašīnmācīšanās algoritmiem ir:
- Lineārā regresija
- Loģistiskā regresija
- Atbalsta vektora mašīnas (SVM)
- K tuvākie kaimiņi (KNN)
- Lēmumu koki
- Nejauši meži
- Mākslīgie neironu tīkli