Kursors SQL Server ir d atabase objekts, kas ļauj mums vienlaikus izgūt katru rindu un manipulēt ar tās datiem . Kursors ir nekas vairāk kā rādītājs uz rindu. To vienmēr izmanto kopā ar SELECT priekšrakstu. Parasti tā ir kolekcija SQL loģika, kas pa vienai iziet cauri iepriekš noteiktam rindu skaitam. Vienkārša kursora ilustrācija ir, ja mums ir plaša darbinieku ierakstu datu bāze un mēs vēlamies aprēķināt katra darbinieka algu pēc nodokļu un atvaļinājumu atskaitīšanas.
SQL serveris kursora mērķis ir atjaunināt datus pēc rindas, mainīt tos vai veikt aprēķinus, kas nav iespējami, kad mēs izgūstam visus ierakstus vienlaikus . Tas ir arī noderīgi, lai veiktu administratīvus uzdevumus, piemēram, SQL Server datu bāzes dublējumkopijas secīgā secībā. Kursori galvenokārt tiek izmantoti izstrādes, DBA un ETL procesos.
Šajā rakstā ir izskaidrots viss par SQL Server kursoru, piemēram, kursora dzīves cikls, kāpēc un kad kursors tiek izmantots, kā ieviest kursorus, to ierobežojumi un kā mēs varam aizstāt kursoru.
Kursora dzīves cikls
Mēs varam aprakstīt kursora dzīves ciklu piecas dažādas sadaļas sekojoši:
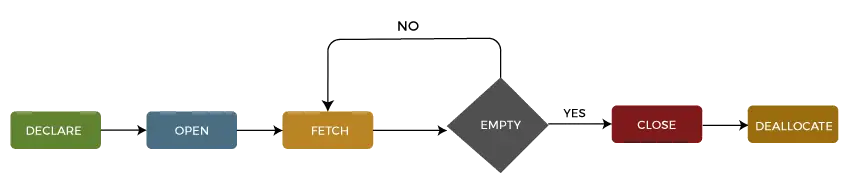
1: deklarēt kursoru
Pirmais solis ir deklarēt kursoru, izmantojot tālāk norādīto SQL priekšrakstu:
java cast int uz virkni
DECLARE cursor_name CURSOR FOR select_statement;
Kursoru varam deklarēt, aiz atslēgvārda DECLARE norādot tā nosaukumu ar datu tipu CURSOR. Pēc tam mēs uzrakstīsim SELECT paziņojumu, kas definē kursora izvadi.
2: atveriet kursoru
Tas ir otrais solis, kurā mēs atveram kursoru, lai saglabātu datus, kas iegūti no rezultātu kopas. Mēs to varam izdarīt, izmantojot tālāk norādīto SQL priekšrakstu:
OPEN cursor_name;
3: ienesiet kursoru
Tas ir trešais solis, kurā rindas var ienest pa vienai vai blokā, lai veiktu datu manipulācijas, piemēram, ievietošanas, atjaunināšanas un dzēšanas darbības pašlaik aktīvajā kursora rindā. Mēs to varam izdarīt, izmantojot tālāk norādīto SQL priekšrakstu:
FETCH NEXT FROM cursor INTO variable_list;
Mēs varam izmantot arī @@FETCHSTATUS funkcija SQL Server, lai iegūtu statusu jaunākajam FETCH priekšraksta kursoram, kas tika izpildīts pret kursoru. The IEŅEMT paziņojums bija veiksmīgs, kad @@FETCHSTATUS izvada nulle. The LAIKĀ paziņojumu var izmantot, lai no kursora izgūtu visus ierakstus. Šis kods to izskaidro skaidrāk:
WHILE @@FETCH_STATUS = 0 BEGIN FETCH NEXT FROM cursor_name; END;
4: aizveriet kursoru
Tas ir ceturtais solis, kurā kursors ir jāaizver pēc tam, kad esam pabeiguši darbu ar kursoru. Mēs to varam izdarīt, izmantojot tālāk norādīto SQL priekšrakstu:
CLOSE cursor_name;
5: Atceliet kursoru
Tas ir piektais un pēdējais solis, kurā mēs izdzēsīsim kursora definīciju un atbrīvosim visus ar kursoru saistītos sistēmas resursus. Mēs to varam izdarīt, izmantojot tālāk norādīto SQL priekšrakstu:
DEALLOCATE cursor_name;
SQL Server kursora lietojumi
Mēs zinām, ka relāciju datu bāzes pārvaldības sistēmas, tostarp SQL Server, lieliski apstrādā datus rindu kopā, ko sauc par rezultātu kopām. Piemēram , mums ir galds product_table kas satur produktu aprakstus. Ja mēs vēlamies atjaunināt cena no produkta, tad tālāk ATJAUNINĀT' vaicājums atjauninās visus ierakstus, kas atbilst nosacījumam KUR' klauzula:
UPDATE product_table SET unit_price = 100 WHERE product_id = 105;
Dažreiz lietojumprogrammai ir jāapstrādā rindas atsevišķi, t.i., pēc rindas, nevis visu rezultātu kopu uzreiz. Mēs varam veikt šo procesu, izmantojot kursorus SQL Server. Pirms kursora izmantošanas mums jāzina, ka kursoru veiktspēja ir ļoti slikta, tāpēc to vienmēr vajadzētu izmantot tikai tad, ja nav citu iespēju, izņemot kursoru.
Kursors izmanto to pašu paņēmienu, kā mēs izmantojam cilpas, piemēram, FOREACH, FOR, WHILE, DO WHILE, lai visās programmēšanas valodās atkārtotu vienu objektu vienlaikus. Tādējādi to varētu izvēlēties, jo tajā tiek izmantota tāda pati loģika kā programmēšanas valodas cilpas process.
kur es varu atrast pārlūkprogrammas iestatījumus
Kursoru veidi SQL serverī
Tālāk ir norādīti dažādi kursoru veidi programmā SQL Server.
- Statiskie kursori
- Dinamiskie kursori
- Kursori tikai uz priekšu
- Keyset kursori

Statiskie kursori
Statiskā kursora parādītā rezultātu kopa vienmēr ir tāda pati kā kursora pirmās atvēršanas brīdī. Tā kā statiskais kursors saglabās rezultātu tempdb , tie ir vienmēr tikai lasīt . Mēs varam izmantot statisko kursoru, lai pārvietotos gan uz priekšu, gan atpakaļ. Atšķirībā no citiem kursoriem, tas ir lēnāks un patērē vairāk atmiņas. Rezultātā mēs to varam izmantot tikai tad, ja ir nepieciešama ritināšana un citi kursori nav piemēroti.
Šis kursors parāda rindas, kas tika noņemtas no datu bāzes pēc tās atvēršanas. Statisks kursors neatspoguļo nekādas INSERT, UPDATE vai DELETE darbības (ja vien kursors nav aizvērts un atkārtoti atvērts).
Dinamiskie kursori
Dinamiskie kursori atrodas pretēji statiskajiem kursoriem, kas ļauj mums veikt datu atjaunināšanas, dzēšanas un ievietošanas darbības, kamēr kursors ir atvērts. Tas ir pēc noklusējuma ritināms . Tas var noteikt visas rezultātu kopas rindās, secībā un vērtībās veiktās izmaiņas neatkarīgi no tā, vai izmaiņas notiek kursora iekšpusē vai ārpus tā. Ārpus kursora mēs nevaram redzēt atjauninājumus, kamēr tie nav apstiprināti.
Kursori tikai uz priekšu
Tas ir noklusējuma un ātrākais kursora veids starp visiem kursoriem. To sauc par tikai uz priekšu vērstu kursoru, jo tas virzās tikai uz priekšu pa rezultātu kopu . Šis kursors neatbalsta ritināšanu. Tas var izgūt tikai rindas no rezultātu kopas sākuma līdz beigām. Tas ļauj mums veikt ievietošanas, atjaunināšanas un dzēšanas darbības. Šeit ir redzama lietotāja veikto ievietošanas, atjaunināšanas un dzēšanas darbību ietekme, kas ietekmē rindas rezultātu kopā, kad rindas tiek izgūtas no kursora. Kad rinda tika ielādēta, mēs nevaram redzēt izmaiņas, kas veiktas rindās, izmantojot kursoru.
Kursori tikai uz priekšu ir iedalīti trīs kategorijās:
- Forward_Only Keyset
- Forward_Only Static
- Ātri uz priekšu

Keyset vadīti kursori
Šī kursora funkcionalitāte atrodas starp statisko un dinamisko kursoru attiecībā uz tās spēju noteikt izmaiņas. Tas ne vienmēr var noteikt izmaiņas rezultātu kopas dalībā un secībā kā statisks kursors. Tas var noteikt izmaiņas rezultātu kopas rindu vērtībās kā dinamisks kursors. Tā var tikai pāriet no pirmās uz pēdējo un pēdējo uz pirmo rindu . Pasūtījums un dalība tiek fiksēti ikreiz, kad tiek atvērts šis kursors.
To darbina unikālo identifikatoru kopa, kas ir tāda pati kā atslēgas kopas atslēgas. Taustiņu kopu nosaka visas rindas, kas kvalificēja SELECT priekšrakstu, kad kursors pirmo reizi tika atvērts. Tā var arī noteikt jebkādas izmaiņas datu avotā, kas atbalsta atjaunināšanas un dzēšanas darbības. Pēc noklusējuma tas ir ritināms.
Piemēra īstenošana
Ieviesīsim kursora piemēru SQL serverī. Mēs to varam izdarīt, vispirms izveidojot tabulu ar nosaukumu ' klientu ' izmantojot tālāk norādīto paziņojumu:
CREATE TABLE customer ( id int PRIMARY KEY, c_name nvarchar(45) NOT NULL, email nvarchar(45) NOT NULL, city nvarchar(25) NOT NULL );
Tālāk tabulā ievietosim vērtības. Mēs varam izpildīt šādu paziņojumu, lai pievienotu datus tabulai:
INSERT INTO customer (id, c_name, email, city) VALUES (1,'Steffen', '[email protected]', 'Texas'), (2, 'Joseph', '[email protected]', 'Alaska'), (3, 'Peter', '[email protected]', 'California'), (4,'Donald', '[email protected]', 'New York'), (5, 'Kevin', '[email protected]', 'Florida'), (6, 'Marielia', '[email protected]', 'Arizona'), (7,'Antonio', '[email protected]', 'New York'), (8, 'Diego', '[email protected]', 'California');
Mēs varam pārbaudīt datus, izpildot ATLASĪT paziņojums, apgalvojums:
SELECT * FROM customer;
Pēc vaicājuma izpildes mēs varam redzēt zemāk esošo izvadi, kur mums ir astoņas rindas tabulā:

Tagad mēs izveidosim kursoru, lai parādītu klientu ierakstus. Tālāk sniegtie koda fragmenti izskaidro visas kursora deklarācijas vai izveides darbības, visu saliekot kopā:
k klasterizācijas algoritms
--Declare the variables for holding data. DECLARE @id INT, @c_name NVARCHAR(50), @city NVARCHAR(50) --Declare and set counter. DECLARE @Counter INT SET @Counter = 1 --Declare a cursor DECLARE PrintCustomers CURSOR FOR SELECT id, c_name, city FROM customer --Open cursor OPEN PrintCustomers --Fetch the record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city --LOOP UNTIL RECORDS ARE AVAILABLE. WHILE @@FETCH_STATUS = 0 BEGIN IF @Counter = 1 BEGIN PRINT 'id' + CHAR(9) + 'c_name' + CHAR(9) + CHAR(9) + 'city' PRINT '--------------------------' END --Print the current record PRINT CAST(@id AS NVARCHAR(10)) + CHAR(9) + @c_name + CHAR(9) + CHAR(9) + @city --Increment the counter variable SET @Counter = @Counter + 1 --Fetch the next record into the variables. FETCH NEXT FROM PrintCustomers INTO @id, @c_name, @city END --Close the cursor CLOSE PrintCustomers --Deallocate the cursor DEALLOCATE PrintCustomers
Pēc kursora izpildes mēs saņemsim šādu izvadi:

SQL Server kursora ierobežojumi
Kursoram ir daži ierobežojumi, tāpēc to vienmēr vajadzētu izmantot tikai tad, ja nav citu iespēju, izņemot kursoru. Šie ierobežojumi ir:
- Kursors patērē tīkla resursus, pieprasot tīkla pārvietošanos turp un atpakaļ katru reizi, kad tas ienes ierakstu.
- Kursors ir norādes, kas atrodas atmiņā, un tas nozīmē, ka tas aizņem zināmu atmiņu, ko mūsu mašīnā varētu izmantot citi procesi.
- Apstrādājot datus, tā uzliek bloķēšanu tabulas daļai vai visai tabulai.
- Kursora veiktspēja un ātrums ir lēnāks, jo tie atjaunina tabulas ierakstus pa vienai rindai.
- Kursori ir ātrāki nekā kamēr cilpas, taču tiem ir vairāk pieskaitāmās izmaksas.
- Kursorā ievietoto rindu un kolonnu skaits ir vēl viens aspekts, kas ietekmē kursora ātrumu. Tas norāda, cik daudz laika nepieciešams, lai atvērtu kursoru un izpildītu ieneses paziņojumu.
Kā mēs varam izvairīties no kursoriem?
Kursoru galvenais uzdevums ir šķērsot tabulu rindu pēc rindas. Vienkāršākais veids, kā izvairīties no kursoriem, ir norādīts zemāk:
SQL kamēr cilpas izmantošana
Vienkāršākais veids, kā izvairīties no kursora izmantošanas, ir izmantot kamēr cilpu, kas ļauj pagaidu tabulā ievietot rezultātu kopu.
Lietotāja definētas funkcijas
Dažreiz kursori tiek izmantoti, lai aprēķinātu iegūto rindu kopu. Mēs varam to paveikt, izmantojot lietotāja definētu funkciju, kas atbilst prasībām.
Savienojumu izmantošana
Join apstrādā tikai tās kolonnas, kas atbilst norādītajam nosacījumam, un tādējādi samazina koda rindiņas, kas nodrošina ātrāku veiktspēju nekā kursori, ja jāapstrādā milzīgi ieraksti.