- dnorm()
dnorm(x, mean, sd)>pnorm()
pnorm(x, mean, sd)>qnorm()
qnorm(p, mean, sd)>rnorm()
rnorm(n, mean, sd)>kur,
– x apzīmē vērtību datu kopu - vidējais (x) apzīmē datu kopas vidējo vērtību x . Tā noklusējuma vērtība ir 0.>– sd(x) apzīmē datu kopas standarta novirzi x . Tā noklusējuma vērtība ir 1.>– n ir novērojumu skaits. – lpp ir varbūtību vektors
Funkcijas, lai radītu normālu sadalījumu R
dnorm()
dnorm()> funkcija R programmēšanā mēra sadalījuma blīvuma funkciju. Statistikā to mēra pēc formulas:>kur,
 ir zemisks un
ir zemisks un 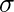 ir standarta novirze. Sintakse :
ir standarta novirze. Sintakse : dnorm(x, mean, sd)>Piemērs:
# creating a sequence of values> # between -15 to 15 with a difference of 0.1> x>=> seq(>->15>,>15>, by>=>0.1>)> > y>=> dnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(>file>=>'dnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |
>
>Izvade:
pnorm()
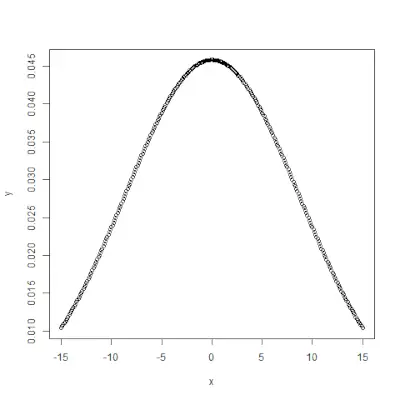
pnorm()> funkcija ir kumulatīvā sadalījuma funkcija, kas mēra varbūtību, ka nejaušam skaitlim X ir vērtība, kas ir mazāka vai vienāda ar x, t.i., statistikā to nosaka>Sintakse:
pnorm(x, mean, sd)>Piemērs:
# creating a sequence of values> # between -10 to 10 with a difference of 0.1> x <>-> seq(>->10>,>10>, by>=>0.1>)> > y <>-> pnorm(x, mean>=> 2.5>, sd>=> 2>)> > # output to be present as PNG file> png(>file>=>'pnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # saving the file> dev.off()> |
>
>Izvade:
qnorm()
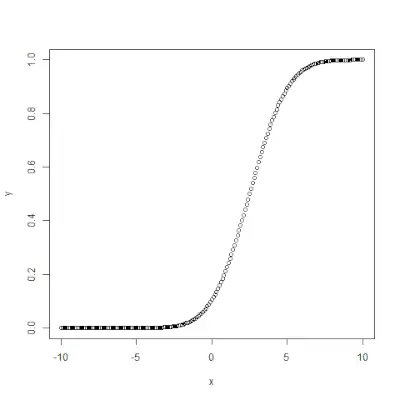
qnorm()> funkcija ir apgriezta pnorm()>funkciju. Tas ņem varbūtības vērtību un dod izvadi, kas atbilst varbūtības vērtībai. Tas ir noderīgi, lai atrastu normālā sadalījuma procentiles. Sintakse: qnorm(p, mean, sd)>Piemērs:
# Create a sequence of probability values> # incrementing by 0.02.> x <>-> seq(>0>,>1>, by>=> 0.02>)> > y <>-> qnorm(x, mean(x), sd(x))> > # output to be present as PNG file> png(>file> => 'qnormExample.webp'>)> > # Plot the graph.> plot(x, y)> > # Save the file.> dev.off()> |
>
>Izvade:
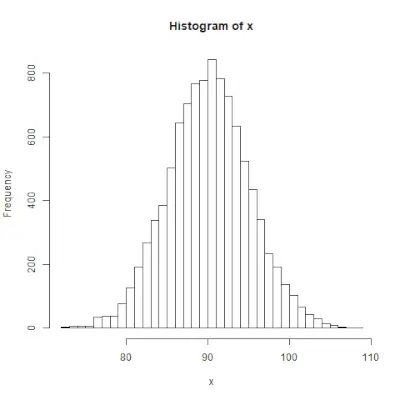
rnorm()
rnorm()> funkcija R programmēšanā tiek izmantota, lai ģenerētu nejaušu skaitļu vektoru, kas parasti ir sadalīti. Sintakse: rnorm(x, mean, sd)>Piemērs:
# Create a vector of 1000 random numbers> # with mean=90 and sd=5> x <>-> rnorm(>10000>, mean>=>90>, sd>=>5>)> > # output to be present as PNG file> png(>file> => 'rnormExample.webp'>)> > # Create the histogram with 50 bars> hist(x, breaks>=>50>)> > # Save the file.> dev.off()> |
>
>Izvade: