BERT, akronīms Transformatoru divvirzienu kodētāja attēlojumiem , ir atvērtā koda avots mašīnmācīšanās sistēma paredzēts sfērai dabiskās valodas apstrāde (NLP) . Šo ietvaru izveidoja 2018. gadā, un to izstrādāja Google AI valodas pētnieki. Raksta mērķis ir izpētīt BERT arhitektūra, darbība un lietojumprogrammas .
Kas ir BERT?
BERT (transformatoru divvirzienu kodētāja attēlojums) izmanto uz transformatoriem balstītu neironu tīklu, lai saprastu un ģenerētu cilvēkam līdzīgu valodu. BERT izmanto tikai kodētāja arhitektūru. Oriģinālā Transformatoru arhitektūra , ir gan kodētāja, gan dekodētāja moduļi. Lēmums izmantot BERT tikai kodētāja arhitektūru liek domāt, ka primārais uzsvars ir jāliek uz ievades secību izpratni, nevis uz izvades secību ģenerēšanu.
BERT divvirzienu pieeja
Tradicionālie valodu modeļi apstrādā tekstu secīgi — no kreisās puses uz labo vai no labās uz kreiso. Šī metode ierobežo modeļa izpratni ar tiešo kontekstu pirms mērķa vārda. BERT izmanto divvirzienu pieeju, ņemot vērā gan vārdu kreiso, gan labo kontekstu teikumā, tā vietā, lai secīgi analizētu tekstu, BERT vienlaikus aplūko visus vārdus teikumā.
Piemērs: krasts atrodas upes _______.
Vienvirziena modelī tukšuma izpratne būtu lielā mērā atkarīga no iepriekšējiem vārdiem, un modelim varētu būt grūti noteikt, vai banka attiecas uz finanšu iestādi vai upes krastu.
BERT, būdams divvirzienu, vienlaikus ņem vērā gan kreiso (krasts atrodas pie upes), gan labo (upes) kontekstu, nodrošinot niansētāku izpratni. Tā saprot, ka trūkstošais vārds, iespējams, ir saistīts ar bankas ģeogrāfisko atrašanās vietu, parādot kontekstuālo bagātību, ko sniedz divvirzienu pieeja.
Iepriekšēja apmācība un precizēšana
BERT modelim tiek veikts divpakāpju process:
- Iepriekšēja apmācība par lielu daudzumu neiezīmēta teksta, lai apgūtu kontekstuālo iegulšanu.
- Precīza pielāgošana marķētiem datiem konkrētiem NLP uzdevumus.
Iepriekšēja apmācība par lieliem datiem
- BERT ir iepriekš apmācīts par lielu daudzumu nemarķētu teksta datu. Modelis apgūst kontekstuālo iegulšanu, kas ir vārdu attēlojums, kas teikumā ņem vērā to apkārtējo kontekstu.
- BERT nodarbojas ar dažādiem bez uzraudzības iepriekšējas apmācības uzdevumiem. Piemēram, tas var iemācīties paredzēt trūkstošos vārdus teikumā (maskētas valodas modelis vai MLM uzdevums), izprast attiecības starp diviem teikumiem vai paredzēt nākamo teikumu pārim.
Marķēto datu precizēšana
- Pēc pirmsapmācības posma BERT modelis, kas ir aprīkots ar kontekstuālo iegulšanu, tiek precīzi noregulēts konkrētiem dabiskās valodas apstrādes (NLP) uzdevumiem. Šis solis pielāgo modeli mērķtiecīgākām lietojumprogrammām, pielāgojot tā vispārējo valodas izpratni konkrētā uzdevuma niansēm.
- BERT ir precīzi noregulēts, izmantojot marķētus datus, kas raksturīgi interesējošo pakārtoto uzdevumu veikšanai. Šie uzdevumi varētu ietvert noskaņojuma analīzi, atbildes uz jautājumiem, nosauktās entītijas atpazīšana , vai jebkuru citu NLP lietojumprogrammu. Modeļa parametri tiek pielāgoti, lai optimizētu tā veiktspēju konkrētā uzdevuma prasībām.
BERT vienotā arhitektūra ļauj tai pielāgoties dažādiem pakārtotiem uzdevumiem ar minimālām izmaiņām, padarot to par daudzpusīgu un ļoti efektīvu rīku dabiskās valodas izpratne un apstrāde.
Kā BERT darbojas?
BERT ir paredzēts valodas modeļa ģenerēšanai, tāpēc tiek izmantots tikai kodētāja mehānisms. Tokenu secība tiek ievadīta transformatora kodētājā. Šie marķieri vispirms tiek iegulti vektoros un pēc tam tiek apstrādāti neironu tīklā. Izvade ir vektoru secība, katrs atbilst ievades pilnvarai, nodrošinot kontekstualizētus attēlojumus.
Apmācot valodu modeļus, prognozēšanas mērķa definēšana ir izaicinājums. Daudzi modeļi paredz nākamo vārdu secībā, kas ir virziena pieeja un var ierobežot konteksta mācīšanos. BERT risina šo izaicinājumu, izmantojot divas novatoriskas apmācības stratēģijas:
- Maskētās valodas modelis (MLM)
- Nākamā teikuma paredzēšana (NSP)
1. Maskas valodas modelis (MLM)
BERT pirmsapmācības procesā daļa vārdu katrā ievades secībā tiek maskēta, un modelis tiek apmācīts paredzēt šo maskēto vārdu sākotnējās vērtības, pamatojoties uz kontekstu, ko nodrošina apkārtējie vārdi.
Vienkāršiem vārdiem sakot,
- Maskējošie vārdi: Pirms BERT mācās no teikumiem, tas paslēpj dažus vārdus (apmēram 15%) un aizstāj tos ar īpašu simbolu, piemēram, [MASK].
- Uzminēt slēptos vārdus: BERT uzdevums ir noskaidrot, kas ir šie slēptie vārdi, aplūkojot vārdus ap tiem. Tā ir kā spēle uzminēt, kur trūkst dažu vārdu, un BERT mēģina aizpildīt tukšās vietas.
- Kā BERT mācās:
- Lai veiktu šos minējumus, BERT pievieno īpašu slāni savai mācību sistēmai. Pēc tam tas pārbauda, cik tuvu tā minējumi ir faktiskajiem slēptajiem vārdiem.
- Tas tiek darīts, pārvēršot savus minējumus varbūtībās, sakot: es domāju, ka šis vārds ir X, un es esmu par to tik pārliecināts.
- Īpaša uzmanība slēptiem vārdiem
- BERT apmācības laikā galvenā uzmanība tiek pievērsta šo slēpto vārdu pareizai noteikšanai. Tas mazāk rūpējas par vārdu prognozēšanu, kas nav slēpti.
- Tas ir tāpēc, ka īstais izaicinājums ir izdomāt trūkstošās daļas, un šī stratēģija palīdz BERT patiešām labi izprast vārdu nozīmi un kontekstu.
Tehniskā ziņā
- BERT pievieno klasifikācijas slāni kodētāja izvadei. Šis slānis ir ļoti svarīgs maskēto vārdu prognozēšanai.
- Klasifikācijas slāņa izvades vektori tiek reizināti ar iegulšanas matricu, pārveidojot tos vārdu krājuma dimensijā. Šis solis palīdz saskaņot paredzētos attēlojumus ar vārdu krājuma telpu.
- Katra vārda varbūtība vārdu krājumā tiek aprēķināta, izmantojot SoftMax aktivizācijas funkcija . Šis solis ģenerē varbūtības sadalījumu pa visu vārdu krājumu katrai maskētajai pozīcijai.
- Apmācības laikā izmantotā zaudējuma funkcija ņem vērā tikai maskēto vērtību prognozēšanu. Modelis tiek sodīts par novirzi starp tā prognozēm un maskēto vārdu faktiskajām vērtībām.
- Modelis konverģē lēnāk nekā virziena modeļi. Tas ir tāpēc, ka apmācības laikā BERT nodarbojas tikai ar maskēto vērtību prognozēšanu, ignorējot nemaskēto vārdu paredzēšanu. Paaugstināta konteksta izpratne, kas panākta, izmantojot šo stratēģiju, kompensē lēnāku konverģenci.
2. Nākamā teikuma pareģošana (NSP)
BERT prognozē, vai otrais teikums ir saistīts ar pirmo. Tas tiek darīts, pārveidojot [CLS] marķiera izvadi 2 × 1 formas vektorā, izmantojot klasifikācijas slāni, un pēc tam, izmantojot SoftMax, aprēķinot varbūtību, vai otrais teikums seko pirmajam.
- Apmācības procesā BERT mācās izprast attiecības starp teikumu pāriem, prognozējot, vai oriģinālajā dokumentā otrais teikums seko pirmajam.
- 50% ievades pāru otrais teikums ir nākamais teikums oriģinālajā dokumentā, bet pārējie 50% ir nejauši izvēlēts teikums.
- Lai palīdzētu modelim atšķirt savienotos un atdalītos teikumu pārus. Ievade tiek apstrādāta pirms modeļa ievadīšanas:
- Pirmā teikuma sākumā tiek ievietots [CLS] marķieris, un katra teikuma beigās tiek pievienots marķieris [SEP].
- Katram marķierim tiek pievienots teikuma iegulšana, kas norāda A vai B teikumu.
- Pozicionāla iegulšana norāda katra marķiera pozīciju secībā.
- BERT prognozē, vai otrais teikums ir saistīts ar pirmo. Tas tiek darīts, pārveidojot [CLS] marķiera izvadi 2 × 1 formas vektorā, izmantojot klasifikācijas slāni, un pēc tam, izmantojot SoftMax, aprēķinot varbūtību, vai otrais teikums seko pirmajam.
BERT modeļa apmācības laikā kopā tiek apmācīts Masked LM un Next Sentence Prediction. Modeļa mērķis ir samazināt maskētā LM un nākamā teikuma prognozēšanas kombinēto zudumu funkciju, tādējādi radot stabilu valodas modeli ar uzlabotām iespējām izprast kontekstu teikumos un attiecībās starp teikumiem.
Kāpēc trenēt Masked LM un Next Sentence Prediction kopā?
Maskētā LM palīdz BERT izprast kontekstu teikuma ietvaros un Nākamā teikuma pareģošana palīdz BERT izprast saistību vai attiecības starp teikumu pāriem. Tādējādi abu stratēģiju apmācība kopā nodrošina, ka BERT apgūst plašu un visaptverošu valodas izpratni, tverot gan teikumu detaļas, gan plūsmu starp teikumiem.
BERT arhitektūra
BERT arhitektūra ir daudzslāņu divvirzienu transformatora kodētājs, kas ir diezgan līdzīgs transformatora modelim. Transformatora arhitektūra ir kodētāja-dekodētāja tīkls, ko izmanto sevis uzmanība kodētāja pusē un uzmanība dekodētāja pusē.
- BERTBĀZEir 1 2 slāņi kodētāja kaudzē kamēr BERTLIELSir 24 slāņi kodētāja kaudzē . Tie ir vairāk nekā sākotnējā dokumentā aprakstītā transformatora arhitektūra ( 6 kodētāja slāņi ).
- BERT arhitektūrām (BASE un LARGE) ir arī lielāki pārvades tīkli (attiecīgi 768 un 1024 slēptās vienības), un vairāk uzmanības galvas (attiecīgi 12 un 16) nekā sākotnējā dokumentā ieteiktā transformatora arhitektūra. Tas satur 512 slēptās vienības un 8 uzmanības galviņas .
- BERTBĀZEsatur 110 miljonus parametru, savukārt BERTLIELSir 340 M parametri.

BERT BASE un BERT LARGE arhitektūra.
Šis modelis aizņem CLS marķieris vispirms kā ievade, pēc tam seko vārdu secība kā ievade. Šeit CLS ir klasifikācijas marķieris. Pēc tam tas nodod ievadi iepriekš minētajiem slāņiem. Katrs slānis tiek piemērots sevis uzmanība un nosūta rezultātu caur pārsūtīšanas tīklu, pēc tam tas tiek nodots nākamajam kodētājam. Modelis izvada slēpta izmēra vektoru ( 768 BERT BASE). Ja mēs vēlamies izvadīt klasifikatoru no šī modeļa, mēs varam ņemt izvadi, kas atbilst CLS pilnvarai.
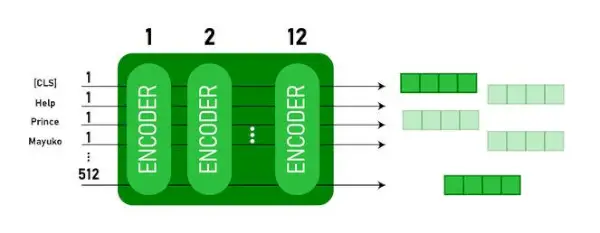
BERT izvade kā iegulšana
Tagad šo apmācīto vektoru var izmantot, lai veiktu vairākus uzdevumus, piemēram, klasificēšanu, tulkošanu utt. Piemēram, papīrs sasniedz lieliskus rezultātus, tikai izmantojot vienu slāni. Neironu tīkls par BERT modeli klasifikācijas uzdevumā.
Kā izmantot BERT modeli NLP?
BERT var izmantot dažādiem dabiskās valodas apstrādes (NLP) uzdevumiem, piemēram:
1. Klasifikācijas uzdevums
- BERT var izmantot tādiem klasifikācijas uzdevumiem kā sentimenta analīze , mērķis ir klasificēt tekstu dažādās kategorijās (pozitīvs/negatīvs/neitrāls), BERT var izmantot, pievienojot klasifikācijas slāni transformatora izvades augšpusē [CLS] marķierim.
- Marķieris [CLS] apzīmē apkopoto informāciju no visas ievades secības. Šo apvienoto attēlojumu pēc tam var izmantot kā ievadi klasifikācijas slānim, lai prognozētu konkrēto uzdevumu.
2. Atbildēšana uz jautājumiem
- Jautājumu atbilžu uzdevumos, kur modelis ir nepieciešams, lai atrastu un atzīmētu atbildi noteiktā teksta secībā, BERT var apmācīt šim nolūkam.
- BERT ir apmācīts atbildēt uz jautājumiem, apgūstot divus papildu vektorus, kas iezīmē atbildes sākumu un beigas. Apmācības laikā modelis tiek nodrošināts ar jautājumiem un atbilstošiem fragmentiem, un tas mācās paredzēt atbildes sākuma un beigu pozīcijas fragmentā.
3. Nosauktā entītijas atpazīšana (NER)
- BERT var izmantot NER, kur mērķis ir identificēt un klasificēt entītijas (piemēram, personu, organizāciju, datumu) teksta secībā.
- Uz BERT balstīts NER modelis tiek apmācīts, ņemot katra transformatora marķiera izvades vektoru un ievadot to klasifikācijas slānī. Slānis paredz katra marķiera nosaukto entītijas etiķeti, norādot entītijas veidu, kuru tas pārstāv.
Kā tokenizēt un kodēt tekstu, izmantojot BERT?
Lai tokenizētu un kodētu tekstu, izmantojot BERT, mēs izmantosim Python bibliotēku “transformators”.
Transformatoru uzstādīšanas komanda:
!pip install transformers>
- Mēs ielādēsim iepriekš apmācīto BERT marķieri ar burtu vārdnīcu, izmantojot BertTokenizer.from_pretrained(bert-base-cased) .
- tokenizer.encode(teksts) marķieri ievades tekstu un pārvērš to marķieru ID secībā.
- drukāt (Token ID:, kodējums) izdrukā pēc kodēšanas iegūtos marķiera ID.
- tokenizer.convert_ids_to_tokens(kodējums) pārvērš token ID atpakaļ to atbilstošajos marķieros.
- drukāt(Tokens:, marķieri) izdrukā tokenus, kas iegūti pēc marķieru ID konvertēšanas
Python3
from> transformers>import> BertTokenizer> # Load pre-trained BERT tokenizer> tokenizer>=> BertTokenizer.from_pretrained(>'bert-base-cased'>)> # Input text> text>=> 'ChatGPT is a language model developed by OpenAI, based on the GPT (Generative Pre-trained Transformer) architecture. '> # Tokenize and encode the text> encoding>=> tokenizer.encode(text)> # Print the token IDs> print>(>'Token IDs:'>, encoding)> # Convert token IDs back to tokens> tokens>=> tokenizer.convert_ids_to_tokens(encoding)> # Print the corresponding tokens> print>(>'Tokens:'>, tokens)> |
>
>
Izvade:
Token IDs: [101, 24705, 1204, 17095, 1942, 1110, 170, 1846, 2235, 1872, 1118, 3353, 1592, 2240, 117, 1359, 1113, 1103, 15175, 1942, 113, 9066, 15306, 11689, 118, 3972, 13809, 23763, 114, 4220, 119, 102] Tokens: ['[CLS]', 'Cha', '##t', '##GP', '##T', 'is', 'a', 'language', 'model', 'developed', 'by', 'Open', '##A', '##I', ',', 'based', 'on', 'the', 'GP', '##T', '(', 'Gene', '##rative', 'Pre', '-', 'trained', 'Trans', '##former', ')', 'architecture', '.', '[SEP]']> The tokenizer.kodēt metode pievieno īpašo [CLS] – klasifikācija un [SEP] – atdalītājs marķieri kodētās secības sākumā un beigās.
BERT piemērošana
BERT izmanto:
- Teksta attēlojums: BERT izmanto, lai ģenerētu vārdu iegulšanu vai vārdu attēlojumu teikumā.
- Nosauktās entītijas atpazīšana (NER) : BERT var precīzi pielāgot nosaukto entītiju atpazīšanas uzdevumiem, kuru mērķis ir noteiktā tekstā identificēt entītijas, piemēram, cilvēku, organizāciju, atrašanās vietu nosaukumus utt.
- Teksta klasifikācija: BERT tiek plaši izmantots teksta klasifikācijas uzdevumiem, tostarp noskaņojuma analīzei, surogātpasta noteikšanai un tēmu kategorizēšanai. Tas ir demonstrējis izcilus rezultātus teksta datu konteksta izpratnē un klasificēšanā.
- Jautājumu atbilžu sistēmas: BERT ir izmantota jautājumu atbilžu sistēmām, kur modelis tiek apmācīts, lai saprastu jautājuma kontekstu un sniegtu atbilstošas atbildes. Tas ir īpaši noderīgi tādiem uzdevumiem kā lasīšanas izpratne.
- Mašīntulkošana: BERT kontekstuālo iegulšanu var izmantot mašīntulkošanas sistēmu uzlabošanai. Modelis atspoguļo valodas nianses, kas ir būtiskas precīzai tulkošanai.
- Teksta kopsavilkums: BERT var izmantot abstraktai teksta apkopošanai, kur modelis ģenerē kodolīgus un saturīgus garāku tekstu kopsavilkumus, izprotot kontekstu un semantiku.
- Sarunu AI: BERT izmanto sarunvalodas AI sistēmu, piemēram, tērzēšanas robotu, virtuālo palīgu un dialogu sistēmu, izveidē. Tā spēja uztvert kontekstu padara to efektīvu, lai izprastu un radītu dabiskās valodas atbildes.
- Semantiskā līdzība: BERT iegulšanu var izmantot, lai izmērītu teikumu vai dokumentu semantisko līdzību. Tas ir vērtīgi tādos uzdevumos kā dublikātu noteikšana, parafrāzes identifikācija un informācijas izguve.
BERT pret GPT
Atšķirība starp BERT un GPT ir šāda:
| BERT | GPT | |
|---|---|---|
| Arhitektūra | BERT ir paredzēts divvirzienu attēlojuma apguvei. Tas izmanto maskēta valodas modeļa mērķi, kur tas prognozē trūkstošos vārdus teikumā, pamatojoties gan uz kreiso, gan labo kontekstu. | Savukārt GPT ir paredzēts ģeneratīvai valodu modelēšanai. Tas paredz nākamo vārdu teikumā, ņemot vērā iepriekšējo kontekstu, izmantojot vienvirziena autoregresīvo pieeju. |
| Pirmsapmācības mērķi | BERT ir iepriekš apmācīts, izmantojot maskēta valodas modeļa mērķi un nākamā teikuma paredzēšanu. Tas koncentrējas uz divvirzienu konteksta tveršanu un attiecību izpratni starp vārdiem teikumā. | GPT ir iepriekš apmācīts paredzēt nākamo vārdu teikumā, kas mudina modeli apgūt saskaņotu valodas attēlojumu un ģenerēt kontekstuāli atbilstošas secības. |
| Konteksta izpratne | BERT ir efektīvs uzdevumiem, kuriem nepieciešama dziļa izpratne par kontekstu un attiecībām teikumā, piemēram, teksta klasifikācija, nosaukto entītiju atpazīšana un atbildes uz jautājumiem. | GPT ir spēcīgs saskanīga un kontekstuāli atbilstoša teksta radīšanā. To bieži izmanto radošos uzdevumos, dialogu sistēmās un uzdevumos, kuros nepieciešama dabiskās valodas secību ģenerēšana. |
| Uzdevumu veidi un lietošanas gadījumi
| Parasti izmanto tādos uzdevumos kā teksta klasifikācija, nosaukto entītiju atpazīšana, noskaņojuma analīze un atbildes uz jautājumiem. | Piemērots tādiem uzdevumiem kā teksta ģenerēšana, dialogu sistēmas, apkopošana un radoša rakstīšana. |
| Precīza regulēšana salīdzinājumā ar dažu kadru apmācību | BERT bieži tiek precīzi pielāgoti konkrētiem pakārtotajiem uzdevumiem ar marķētiem datiem, lai pielāgotu savus iepriekš sagatavotos attēlojumus konkrētajam uzdevumam. | GPT ir izstrādāts, lai veiktu dažu kadru apmācību, kur to var vispārināt uz jauniem uzdevumiem ar minimāliem uzdevumiem raksturīgiem apmācības datiem. |
Pārbaudiet arī:
- Sentimenta klasifikācija, izmantojot BERT
- Kā ģenerēt Word iegulšanu, izmantojot BERT?
- BART modelis teksta automātiskai pabeigšanai NLP
- Toksisko komentāru klasifikācija, izmantojot BERT
- Nākamā teikuma paredzēšana, izmantojot BERT
Bieži uzdotie jautājumi (FAQ)
J. Kam izmanto BERT?
BERT izmanto NLP uzdevumu veikšanai, piemēram, teksta attēlošanai, nosaukto entītiju atpazīšanai, teksta klasifikācijai, jautājumu un atbilžu sistēmām, mašīntulkošanai, teksta apkopošanai un citiem.
J. Kādas ir BERT modeļa priekšrocības?
BERT valodas modelis izceļas ar plašo iepriekšēju apmācību vairākās valodās, piedāvājot plašu lingvistisko pārklājumu salīdzinājumā ar citiem modeļiem. Tas padara BERT īpaši izdevīgu projektos, kas nav balstīti uz angļu valodu, jo tas nodrošina stabilu kontekstuālo attēlojumu un semantisko izpratni dažādās valodās, uzlabojot tās daudzpusību daudzvalodu lietojumprogrammās.
J. Kā BERT darbojas noskaņojuma analīzē?
BERT izceļas ar sentimenta analīzi, izmantojot divvirzienu attēlojuma mācīšanos, lai noteiktā tekstā uztvertu kontekstuālās nianses, semantiskās nozīmes un sintaktiskās struktūras. Tas ļauj BERT izprast teikumā izteikto noskaņojumu, ņemot vērā vārdu attiecības, kā rezultātā tiek iegūti ļoti efektīvi sentimenta analīzes rezultāti.
10 miljoni
J. Vai Google pamatā ir BERT?
BERT un RankBrain ir Google meklēšanas algoritma sastāvdaļas, lai apstrādātu vaicājumus un tīmekļa lapu saturu, lai iegūtu labāku izpratni un uzlabotu meklēšanas rezultātus.