Kopš datoru izgudrošanas cilvēki ir lietojuši terminu ' Dati “, lai atsauktos uz datora informāciju, kas tiek pārraidīta vai saglabāta. Tomēr ir dati, kas pastāv arī pasūtījumu veidos. Dati var būt skaitļi vai teksti, kas uzrakstīti uz papīra lapas bitu un baitu veidā, kas tiek glabāti elektronisko ierīču atmiņā, vai fakti, kas glabājas cilvēka prātā. Kad pasaule sāka modernizēties, šie dati kļuva par nozīmīgu ikviena ikdienas dzīves aspektu, un dažādas ieviešanas ļāva tos uzglabāt atšķirīgi.
Dati ir faktu un skaitļu kopums vai vērtību vai noteikta formāta vērtību kopa, kas attiecas uz vienu vienumu vērtību kopu. Pēc tam datu vienumi tiek klasificēti apakšposteņos, kas ir vienumu grupa, kas nav zināma kā vienkārša elementa primārā forma.
Apskatīsim piemēru, kurā darbinieka vārdu var iedalīt trīs apakšpozīcijās: pirmais, vidējais un pēdējais. Tomēr darbiniekam piešķirtais ID parasti tiks uzskatīts par vienu vienumu.
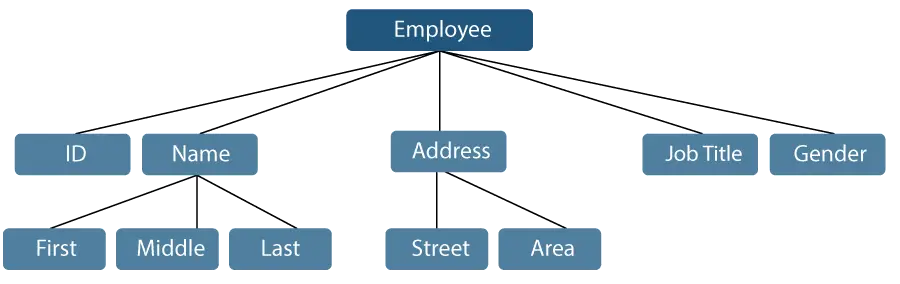
1. attēls: Datu vienumu attēlojums
Iepriekš minētajā piemērā tādi vienumi kā ID, vecums, dzimums, pirmais, vidējais, pēdējais, iela, atrašanās vieta utt. ir elementāri datu vienumi. Turpretim nosaukums un adrese ir grupas datu vienumi.
Kas ir datu struktūra?
Datu struktūra ir datorzinātņu nozare. Datu struktūras izpēte ļauj izprast datu organizāciju un datu plūsmas pārvaldību, lai paaugstinātu jebkura procesa vai programmas efektivitāti. Datu struktūra ir īpašs veids, kā saglabāt un kārtot datus datora atmiņā, lai šos datus varētu viegli izgūt un vajadzības gadījumā efektīvi izmantot nākotnē. Datus var pārvaldīt dažādos veidos, piemēram, loģiskais vai matemātiskais modelis konkrētai datu organizācijai ir pazīstams kā datu struktūra.
Konkrēta datu modeļa apjoms ir atkarīgs no diviem faktoriem:
- Pirmkārt, tas ir pietiekami ielādēts struktūrā, lai atspoguļotu noteiktu datu korelāciju ar reālās pasaules objektu.
- Otrkārt, veidošanai jābūt tik vienkāršai, lai vajadzības gadījumā varētu pielāgoties datu efektīvai apstrādei.
Daži datu struktūru piemēri ir masīvi, saistītie saraksti, kaudze, rinda, koki utt. Datu struktūras tiek plaši izmantotas gandrīz visos datorzinātņu aspektos, t.i., kompilatoru dizainā, operētājsistēmās, grafikā, mākslīgajā intelektā un daudzos citos aspektos.
Datu struktūras ir daudzu datorzinātņu algoritmu galvenā daļa, jo tās ļauj programmētājiem efektīvi pārvaldīt datus. Tam ir izšķiroša nozīme programmas vai programmatūras veiktspējas uzlabošanā, jo programmatūras galvenais mērķis ir pēc iespējas ātrāk uzglabāt un izgūt lietotāja datus.
pasvītrot, izmantojot css
Ar datu struktūrām saistītās pamatterminoloģijas
Datu struktūras ir jebkuras programmatūras vai programmas pamatelementi. Programmai piemērotas datu struktūras izvēle programmētājam ir ārkārtīgi sarežģīts uzdevums.
Tālāk ir norādītas dažas pamata terminoloģijas, kas tiek izmantotas ikreiz, kad ir iesaistītas datu struktūras.
| Atribūti | ID | Vārds | Dzimums | Amata nosaukums |
|---|---|---|---|---|
| Vērtības | 1234. gads | Steisija M. Hila | Sieviete | Programmatūras izstrādātājs |
Entītijas ar līdzīgiem atribūtiem veido an Entītiju kopa . Katram entītiju kopas atribūtam ir vērtību diapazons, visu iespējamo vērtību kopa, ko varētu piešķirt konkrētajam atribūtam.
Termins “informācija” dažkārt tiek izmantots datiem ar noteiktiem nozīmīgu vai apstrādātu datu atribūtiem.
Izpratne par datu struktūru nepieciešamību
Lietojumprogrammas kļūst arvien sarežģītākas un datu apjoms katru dienu palielinās, kas var radīt problēmas ar datu meklēšanu, apstrādes ātrumu, vairāku pieprasījumu apstrādi un daudz ko citu. Datu struktūras atbalsta dažādas metodes, lai efektīvi organizētu, pārvaldītu un uzglabātu datus. Izmantojot datu struktūras, mēs varam viegli šķērsot datu vienumus. Datu struktūras nodrošina efektivitāti, atkārtotu izmantošanu un abstrakciju.
Kāpēc mums vajadzētu mācīties datu struktūras?
- Datu struktūras un algoritmi ir divi no galvenajiem datorzinātņu aspektiem.
- Datu struktūras ļauj mums sakārtot un uzglabāt datus, savukārt algoritmi ļauj apstrādāt šos datus jēgpilni.
- Datu struktūru un algoritmu apgūšana palīdzēs mums kļūt par labākiem programmētājiem.
- Mēs varēsim uzrakstīt kodu, kas ir efektīvāks un uzticamāks.
- Mēs arī spēsim ātrāk un efektīvāk atrisināt problēmas.
Datu struktūru mērķu izpratne
Datu struktūras atbilst diviem papildu mērķiem:
Izpratne par dažām datu struktūru galvenajām iezīmēm
Dažas no nozīmīgajām datu struktūru iezīmēm ir:
Datu struktūru klasifikācija
Datu struktūra nodrošina strukturētu mainīgo lielumu kopu, kas dažādos veidos ir savstarpēji saistīti. Tas veido pamatu programmēšanas rīkam, kas apzīmē attiecības starp datu elementiem un ļauj programmētājiem efektīvi apstrādāt datus.
Mēs varam klasificēt datu struktūras divās kategorijās:
listnode
- Primitīvā datu struktūra
- Neprimitīvā datu struktūra
Nākamajā attēlā parādītas dažādas datu struktūru klasifikācijas.

2. attēls: Datu struktūru klasifikācijas
Primitīvās datu struktūras
- Šīs datu struktūras var manipulēt vai darbināt tieši ar mašīnas līmeņa instrukcijām.
- Pamatdatu veidi, piemēram Vesels skaitlis, pludiņš, rakstzīme , un Būla ietilpst primitīvajās datu struktūrās.
- Šos datu tipus sauc arī par Vienkārši datu veidi , jo tajos ir rakstzīmes, kuras nevar sadalīt tālāk
Neprimitīvas datu struktūras
- Šīs datu struktūras nevar manipulēt vai darbināt tieši ar mašīnas līmeņa instrukcijām.
- Šo datu struktūru galvenā uzmanība tiek pievērsta datu elementu kopas veidošanai, kas ir vai nu viendabīgs (tas pats datu tips) vai neviendabīgs (dažādi datu veidi).
- Pamatojoties uz datu struktūru un izkārtojumu, šīs datu struktūras varam iedalīt divās apakškategorijās –
- Lineārās datu struktūras
- Nelineāras datu struktūras
Lineārās datu struktūras
Datu struktūra, kas saglabā lineāru savienojumu starp datu elementiem, ir pazīstama kā lineāra datu struktūra. Datu izkārtojums tiek veikts lineāri, kur katrs elements sastāv no pēctečiem un priekštečiem, izņemot pirmo un pēdējo datu elementu. Tomēr tas ne vienmēr ir taisnība atmiņas gadījumā, jo izkārtojums var nebūt secīgs.
Pamatojoties uz atmiņas sadalījumu, lineārās datu struktūras tiek iedalītas divos veidos:
The Masīvs ir labākais statiskās datu struktūras piemērs, jo tām ir fiksēts lielums, un tās datus vēlāk var modificēt.
Saistītie saraksti, skursteņi , un Astes ir izplatīti dinamisku datu struktūru piemēri
Lineāro datu struktūru veidi
Tālāk ir sniegts saraksts ar lineārajām datu struktūrām, kuras mēs parasti izmantojam:
1. Masīvi
An Masīvs ir datu struktūra, ko izmanto, lai vienā mainīgajā apkopotu vairākus viena veida datu elementus. Tā vietā, lai saglabātu vairākas viena un tā paša datu tipu vērtības atsevišķos mainīgo nosaukumos, mēs varētu tās visas saglabāt vienā mainīgajā. Šis apgalvojums nenozīmē, ka mums būs jāapvieno visas viena un tā paša datu tipa vērtības jebkurā programmā vienā šī datu tipa masīvā. Taču bieži vien daži konkrēti viena un tā paša datu tipu mainīgie ir saistīti viens ar otru masīvam piemērotā veidā.
Masīvs ir elementu saraksts, kurā katram elementam ir unikāla vieta sarakstā. Masīva datu elementiem ir vienāds mainīgā nosaukums; tomēr katram ir atšķirīgs indeksa numurs, ko sauc par apakšindeksu. Mēs varam piekļūt jebkuram datu elementam no saraksta, izmantojot tā atrašanās vietu sarakstā. Tādējādi masīvu galvenā iezīme, kas jāsaprot, ir tāda, ka dati tiek glabāti blakus esošās atmiņas vietās, ļaujot lietotājiem pārvietoties pa masīva datu elementiem, izmantojot to attiecīgos indeksus.

3. attēls. Masīvs
Masīvus var iedalīt dažādos veidos:
Dažas masīva lietojumprogrammas:
- Mēs varam saglabāt datu elementu sarakstu, kas pieder vienam datu tipam.
- Masīvs darbojas kā papildu krātuve citām datu struktūrām.
- Masīvs palīdz arī saglabāt fiksētā skaita binārā koka datu elementus.
- Masīvs darbojas arī kā matricu krātuve.
2. Saistītie saraksti
A Saistītais saraksts ir vēl viens piemērs lineārai datu struktūrai, ko izmanto datu elementu kolekcijas dinamiskai glabāšanai. Datu elementus šajā datu struktūrā attēlo mezgli, kas savienoti, izmantojot saites vai norādes. Katrā mezglā ir divi lauki, informācijas lauks sastāv no faktiskiem datiem, un rādītāja lauks sastāv no nākamo saraksta mezglu adreses. Saistītā saraksta pēdējā mezgla rādītājs sastāv no nulles rādītāja, jo tas norāda uz neko. Atšķirībā no masīviem lietotājs var dinamiski pielāgot saistītā saraksta izmēru atbilstoši prasībām.
saulains deols

4. attēls. Saistīts saraksts
Saistītos sarakstus var iedalīt dažādos veidos:
Dažas saistīto sarakstu lietojumprogrammas:
- Saistītie saraksti palīdz mums ieviest iepriekš noteikta izmēra stekus, rindas, bināros kokus un grafikus.
- Varam ieviest arī operētājsistēmas funkciju dinamiskai atmiņas pārvaldībai.
- Saistītie saraksti pieļauj arī matemātisku darbību polinomu ieviešanu.
- Mēs varam izmantot Circular Linked List, lai ieviestu operētājsistēmas vai lietojumprogrammu funkcijas, kas nodrošina uzdevumu izpildi.
- Apļveida saistītais saraksts ir noderīgs arī slaidrādē, kurā lietotājam pēc pēdējā slaida ir jāatgriežas pie pirmā slaida.
- Divkārši saistīts saraksts tiek izmantots, lai pārlūkprogrammā ieviestu pogas uz priekšu un atpakaļ, lai pārvietotos uz priekšu un atpakaļ atvērtajās vietnes lapās.
3. Kaudzītes
A Kaudze ir lineāra datu struktūra, kas seko LIFO (Last In, First Out) princips, kas ļauj veikt tādas darbības kā ievietošana un dzēšana no viena steka gala, t.i., no augšas. Stackus var ieviest, izmantojot blakus esošo atmiņu, masīvu un nesaistīto atmiņu, saistīto sarakstu. Reāli Stacks piemēri ir grāmatu kaudzes, kāršu komplekts, naudas kaudzes un daudz kas cits.

5. attēls. Stacka piemērs dzīvē
Iepriekš redzamajā attēlā ir parādīts kaudzes reāls piemērs, kur darbības tiek veiktas tikai no viena gala, piemēram, jaunu grāmatu ievietošana un noņemšana no kaudzes augšdaļas. Tas nozīmē, ka ievietošanu un dzēšanu kaudzē var veikt tikai no steka augšdaļas. Mēs jebkurā laikā varam piekļūt tikai Stack virsotnēm.
Galvenās operācijas stekā ir šādas:

6. attēls. Stack
Daži steku pielietojumi:
- Stack tiek izmantots kā pagaidu krātuves struktūra rekursīvām operācijām.
- Stack tiek izmantots arī kā papildu krātuves struktūra funkciju izsaukumiem, ligzdotām darbībām un atliktajām/atliktajām funkcijām.
- Mēs varam pārvaldīt funkciju zvanus, izmantojot Stacks.
- Stacki tiek izmantoti arī, lai novērtētu aritmētiskās izteiksmes dažādās programmēšanas valodās.
- Stacki ir noderīgi arī, lai pārveidotu infix izteiksmes par postfix izteiksmēm.
- Stacki ļauj mums pārbaudīt izteiksmes sintaksi programmēšanas vidē.
- Mēs varam saskaņot iekavas, izmantojot Stacks.
- Stackus var izmantot, lai apgrieztu virkni.
- Stacki ir noderīgi, risinot problēmas, kuru pamatā ir atkāpšanās.
- Mēs varam izmantot Stacks padziļinātajā meklēšanā grafikā un kokā.
- Stacki tiek izmantoti arī operētājsistēmas funkcijās.
- Kaudzītes tiek izmantotas arī rediģēšanas funkcijās UNDO un REDO.
4. Astes
A Rinda ir lineāra datu struktūra, kas līdzīga stekam ar dažiem elementu ievietošanas un dzēšanas ierobežojumiem. Elementa ievietošana rindā tiek veikta vienā galā, un noņemšana tiek veikta citā vai pretējā galā. Tādējādi mēs varam secināt, ka rindas datu struktūra ievēro FIFO (First In, First Out) principu, lai manipulētu ar datu elementiem. Rindu ieviešanu var veikt, izmantojot masīvus, saistītos sarakstus vai skursteņus. Daži rindu piemēri dzīvē ir rinda pie biļešu kases, eskalators, automazgātava un daudz kas cits.

7. attēls. Reāls rindas piemērs
Iepriekš redzamajā attēlā ir reāli ilustrēts filmu biļešu skaitītājs, kas var palīdzēt mums saprast rindu, kurā pirmais vienmēr tiek apkalpots pirmais klients. Klients, kurš ieradīsies pēdējais, neapšaubāmi tiks apkalpots pēdējais. Abi rindas gali ir atvērti un var izpildīt dažādas darbības. Vēl viens piemērs ir pārtikas tiesas līnija, kurā klients tiek ievietots no aizmugures, bet klients tiek noņemts priekšgalā pēc tam, kad ir sniegts pakalpojums, ko viņš lūdza.
Šīs ir rindas galvenās darbības:

8. attēls. Rinda
Daži rindu lietojumi:
- Rindas parasti tiek izmantotas platuma meklēšanas operācijā Graphs.
- Rindas tiek izmantotas arī operētājsistēmu darbu plānotāja darbībās, piemēram, tastatūras bufera rinda, lai saglabātu lietotāju nospiestos taustiņus, un drukas bufera rinda, lai saglabātu printera izdrukātos dokumentus.
- Rindas ir atbildīgas par CPU plānošanu, darba plānošanu un diska plānošanu.
- Prioritātes rindas tiek izmantotas failu lejupielādes operācijās pārlūkprogrammā.
- Rindas tiek izmantotas arī datu pārsūtīšanai starp perifērijas ierīcēm un centrālo procesoru.
- Rindas ir atbildīgas arī par CPU lietotāju lietojumprogrammu radīto pārtraukumu apstrādi.
Nelineāras datu struktūras
Nelineārās datu struktūras ir datu struktūras, kurās datu elementi nav sakārtoti secīgā secībā. Šeit datu ievietošana un noņemšana nav iespējama lineārā veidā. Starp atsevišķiem datu vienumiem pastāv hierarhiskas attiecības.
Nelineāro datu struktūru veidi
Tālāk ir sniegts to nelineāro datu struktūru saraksts, kuras mēs parasti izmantojam.
saraksts uz java
1. Koki
Koks ir nelineāra datu struktūra un hierarhija, kas satur tādu mezglu kolekciju, kurā katrs koka mezgls saglabā vērtību un atsauču sarakstu uz citiem mezgliem (“bērniem”).
Koka datu struktūra ir specializēta metode datu kārtošanai un apkopošanai datorā, lai tos izmantotu efektīvāk. Tajā ir centrālais mezgls, strukturālie mezgli un apakšmezgli, kas savienoti ar malām. Mēs varam arī teikt, ka koka datu struktūra sastāv no saknēm, zariem un lapām, kas ir savienotas.

9. attēls. Koks
Kokus var iedalīt dažādos veidos:
Daži koku pielietojumi:
- Koki ievieš hierarhiskas struktūras datorsistēmās, piemēram, direktorijos un failu sistēmās.
- Koki tiek izmantoti arī vietnes navigācijas struktūras ieviešanai.
- Mēs varam ģenerēt kodu, piemēram, Hafmena kodu, izmantojot kokus.
- Koki ir noderīgi arī lēmumu pieņemšanā spēļu lietojumprogrammās.
- Koki ir atbildīgi par prioritāro rindu ieviešanu uz prioritātēm balstītām OS plānošanas funkcijām.
- Koki ir atbildīgi arī par izteiksmju un paziņojumu parsēšanu dažādu programmēšanas valodu kompilatoros.
- Mēs varam izmantot kokus, lai saglabātu datu atslēgas datu bāzes pārvaldības sistēmas (DBMS) indeksēšanai.
- Spanning Trees ļauj mums maršrutēt lēmumus datoru un sakaru tīklos.
- Koki tiek izmantoti arī ceļa meklēšanas algoritmā, kas ieviests mākslīgā intelekta (AI), robotikas un videospēļu lietojumprogrammās.
2. Grafiki
Grafs ir vēl viens nelineāras datu struktūras piemērs, kas ietver ierobežotu skaitu mezglu vai virsotņu un tos savienojošās malas. Grafikus izmanto, lai risinātu reālās pasaules problēmas, kurās tie apzīmē problēmas apgabalu kā tīklu, piemēram, sociālos tīklus, ķēdes tīklus un tālruņu tīklus. Piemēram, diagrammas mezgli vai virsotnes var attēlot vienu lietotāju telefona tīklā, bet malas attēlo saikni starp tiem, izmantojot tālruni.
Grafika datu struktūra G tiek uzskatīta par matemātisko struktūru, kas sastāv no virsotņu kopas V un malu kopas E, kā parādīts tālāk:
G = (V,E)

10. attēls. Grafiks
Iepriekš redzamais attēls attēlo grafiku ar septiņām virsotnēm A, B, C, D, E, F, G un desmit malām [A, B], [A, C], [B, C], [B, D], [B, E], [C, D], [D, E], [D, F], [E, F] un [E, G].
Atkarībā no virsotņu un šķautņu atrašanās vietas grafikus var iedalīt dažādos veidos:
Daži grafiku pielietojumi:
- Grafiki palīdz mums attēlot maršrutus un tīklus transporta, ceļojumu un sakaru lietojumprogrammās.
- Grafikus izmanto, lai parādītu maršrutus GPS.
- Grafiki arī palīdz mums attēlot savstarpējos savienojumus sociālajos tīklos un citās tīkla lietojumprogrammās.
- Grafikus izmanto kartēšanas lietojumprogrammās.
- Grafiki ir atbildīgi par lietotāja preferenču attēlojumu e-komercijas lietojumprogrammās.
- Grafikus izmanto arī komunālajos tīklos, lai identificētu vietējām vai pašvaldību korporācijām radītās problēmas.
- Grafiki palīdz arī pārvaldīt resursu izmantošanu un pieejamību organizācijā.
- Grafikus izmanto arī, lai izveidotu vietņu dokumentu saišu kartes, lai parādītu savienojumu starp lapām, izmantojot hipersaites.
- Grafikus izmanto arī robotu kustībās un neironu tīklos.
Datu struktūru pamatoperācijas
Nākamajā sadaļā mēs apspriedīsim dažāda veida darbības, kuras varam veikt, lai manipulētu ar datiem katrā datu struktūrā:
- Kompilēšanas laiks
- Izpildes laiks
Piemēram, malloc () funkcija tiek izmantota C valodā, lai izveidotu datu struktūru.
Izpratne par abstrakto datu tipu
Saskaņā ar Nacionālais standartu un tehnoloģiju institūts (NIST) , datu struktūra ir informācijas izkārtojums, parasti atmiņā, lai uzlabotu algoritma efektivitāti. Datu struktūras ietver saistītos sarakstus, stekas, rindas, kokus un vārdnīcas. Tās varētu būt arī teorētiskas vienības, piemēram, personas vārds un adrese.
No iepriekš minētās definīcijas mēs varam secināt, ka darbības datu struktūrā ietver:
- Augsts abstrakciju līmenis, piemēram, vienuma pievienošana vai dzēšana no saraksta.
- Vienuma meklēšana un kārtošana sarakstā.
- Piekļuve visaugstākās prioritātes vienumam sarakstā.
Ikreiz, kad datu struktūra veic šādas darbības, to sauc par an Abstract Data Type (ADT) .
Mēs to varam definēt kā datu elementu kopu kopā ar darbībām ar datiem. Termins “abstrakts” attiecas uz faktu, ka dati un tajos definētās pamatoperācijas tiek pētītas neatkarīgi no to ieviešanas. Tas ietver to, ko mēs varam darīt ar datiem, nevis to, kā mēs varam to darīt.
mvc java
ADI ieviešana satur krātuves struktūru, lai saglabātu datu elementus un algoritmus pamatdarbībai. Visas datu struktūras, piemēram, masīvs, saistītais saraksts, rinda, kaudze utt., ir ADT piemēri.
Izpratne par ADT izmantošanas priekšrocībām
Reālajā pasaulē programmas attīstās jaunu ierobežojumu vai prasību rezultātā, tāpēc, lai mainītu programmu, parasti ir jāmaina viena vai vairākas datu struktūras. Piemēram, pieņemsim, ka vēlamies darbinieka ierakstā ievietot jaunu lauku, lai izsekotu sīkākai informācijai par katru darbinieku. Tādā gadījumā mēs varam uzlabot programmas efektivitāti, aizstājot masīvu ar saistīto struktūru. Šādā situācijā nav piemērota katras procedūras pārrakstīšana, kas izmanto modificēto struktūru. Tādējādi labāka alternatīva ir atdalīt datu struktūru no tās ieviešanas informācijas. Šis ir abstrakto datu tipu (ADT) izmantošanas princips.
Daži datu struktūru lietojumi
Tālāk ir norādītas dažas datu struktūru lietojumprogrammas.
- Datu struktūras palīdz sakārtot datus datora atmiņā.
- Datu struktūras palīdz arī attēlot informāciju datu bāzēs.
- Datu struktūras ļauj ieviest algoritmus, lai meklētu datus (piemēram, meklētājprogrammu).
- Mēs varam izmantot datu struktūras, lai ieviestu algoritmus manipulēšanai ar datiem (piemēram, tekstapstrādes programmas).
- Mēs varam arī ieviest algoritmus datu analīzei, izmantojot datu struktūras (piemēram, datu ieguves rīkus).
- Datu struktūras atbalsta algoritmus datu ģenerēšanai (piemēram, nejaušo skaitļu ģenerators).
- Datu struktūras atbalsta arī algoritmus datu saspiešanai un atspiešanai (piemēram, zip utilīta).
- Mēs varam arī izmantot datu struktūras, lai ieviestu algoritmus datu šifrēšanai un atšifrēšanai (piemēram, drošības sistēma).
- Ar Data Structures palīdzību mēs varam izveidot programmatūru, kas var pārvaldīt failus un direktorijus (piemēram, failu pārvaldnieks).
- Mēs varam arī izstrādāt programmatūru, kas var atveidot grafiku, izmantojot datu struktūras. (Piemēram, tīmekļa pārlūkprogramma vai 3D renderēšanas programmatūra).
Papildus tām, kā minēts iepriekš, ir arī daudzas citas datu struktūru lietojumprogrammas, kas var palīdzēt mums izveidot jebkuru vēlamo programmatūru.